
티스토리 뷰

-
소개
캐치딜 서비스는 2019년 10월부터 시작된 토이프로젝트의 일환으로, 같은 대학 주니어 대학생 3명이서 똘똘뭉쳐 제작된 프로젝트입니다.
캐치딜은 여러 플랫폼(뽐뿌, 클리앙 등)에 퍼져있는 핫딜특가 데이터를 Selenium 크롤링을 통해 데이터를 수집해서 보여주는 서비스입니다.
-
서버 선택의 기로
캐치딜을 처음 개발을 할 때 때 있어서 어떤 플랫폼 서버를 써야할지 큰 기로에 빠지게 되었습니다.
저는 서버를 선택함에 있어서 아래 사항을 중점으로 고민을 하게 됩니다.
- 가격이 합리적인가? (최대한 Low Price였으면 좋겠다.)
- Ruby를 기본으로 지원해주는가? (캐치딜은 웹서버가 Ruby on Rails 기반입니다.)
- 내가 쉽게 다룰 수 있는가?
개인적으로 저는 아래 두 플랫폼을 유심히 봤습니다.


일단 국내 서버플랫폼을 유심히 보지 않은 이유는
1. 비합리적인 가격
* 국내 서버 플랫폼은 대부분 트래픽에 따른 가격이 책정이 됩니다, 예를들어 [월 10000원/5GB 트래픽] 서버를 구매했지만 3GB밖에 안썼어도 돈은 만원씩 내야 합니다.
2. Ruby를 지원하는 호스팅 업체는 극히 드뭄
3. 무료지원 부족 (AWS 및 Heroku는 학생에게 크레딧을 지원해서 무료로 서비스를 이용할 수 있게 합니다.)
이 3가지 때문이었습니다.
-
처음 첫 서버의 시작은 헤로쿠

그리하여 어째어째 저는 Heroku를 선택하게 되었습니다.
Heroku를 선택한 이유는 다음과 같습니다.
-
일단 기본 사용은 무료 (유료 서버 사용에 있어 Github Student Pack 인증 시 매 달 고정적으로 7달러, 최대 2년 지원)
-
서버 사용금액에 있어 한국의 주요 호스팅 서비스와 같이 사전에 서비스 이용금액을 계약하는게 아닌, 일단 쓰고 나중에 서비스를 사용한 만큼 돈이 부과
-
서버 배포의 자동화
-
Ruby 지원
처음엔 무난하게 헤로쿠를 잘 써왔습니다.
하지만 헤로쿠를 쓰면서 점점 뭔가 문제에 봉착하게 됩니다.
1. Scheduler Job 시간 설정 선택권

헤로쿠에서는 터미널에 Cronjob이 지원되질 않다보니 별도로 Scheduler 모듈을 설치해서 써야하는 문제점이 있습니다.
부록 Scheduler Background Job [클릭]
하지만 이 Scheduler는 시간을 서버 관리자가 마음대로 정하질 못한다는 문제점이 있습니다.
2. 무료 Heroku 서버에서는 여러 Scheduler Job 수행이 불가
Heroku에서 무료로 제공해주는 서버 같은 경우는 하나의 Job이 실행되는 도중에는 다른 Job이 실행되질 못합니다.
Scheduler Job 같은 경우에는 동일 시간대에 여러개의 Job이 돌아갈 확률이 많습니다.
Job 상황 예시
13시 10분 Job : 크롤링 Job Running (소요시간 : 약 5분)
13시 11분 Job : 30일이 지난 옛날 데이터 삭제
하지만 위와같은 상황이 발생할 경우 13시 11분에 실행될 Job은 안돌아간다는 문제점이 발생합니다.
캐치딜은 크롤링 기술이 핵심으로 사용되는 컨텐츠인 만큼 크롤러를 관리하는 스케쥴러의 역할이 큽니다. 하지만 위와같은 상황으로 인해 크롤러의 부재가 발생되서는 안됩니다.
그래서 이 때 어쩔 수 없이 Heroku의 유료서버 서비스를 사용하기 시작합니다.
(단, 학생혜택을 통해 최대한 무료로 쓰는 선으로!)
3. Database를 마음대로 설정 불가
Heroku는 프로젝트를 배포만 하면 헤로쿠 내부에서 모든 설정이 자동으로 이루어집니다. 하지만 이 것이 장점이자 단점이 될 줄은 꿈에도 몰랐던게, Database 설정에 대해서도 내 마음대로 설정을 못하고 Heroku 내에서 강제로 설정이 됩니다. 그렇다보니 외부에서 Heroku DB 내로 접근을 할 수 없다는 문제점이 있었습니다.
외부에서 헤로쿠 DB와 Remote Connect 하는 방법이 있을 것 같긴 하지만, 이미 이걸 생각해내기엔 늦은 상황이었습니다.
4. 비용
결정적으로 Heroku에서 다른 서비스로 서버를 옮기게 된 계기입니다.
앞서 말했다 싶이 Heroku는 Github Student Pack을 인증 시, 지금 사용하는 서비스가 유료 서비스일지라도 기본 호스팅 비용에 대해선 7달러 내에서는 무료로 지원해주는 지원제도가 있습니다.
확실히 서버에 대해서는 지원을 받았습니다,
그런데 여기서 문제가 터집니다.

Heroku 서버에는 기본적으로 Cronjob이 깔려있지 않다보니, 헤로쿠에서 자체적으로 지원하는 scheduler Job(Add On)을 이용해서 Scheduler 작업을 돌립니다.
모듈은 무료서버를 사용 시, 금액이 부가가 되진 않았습니다. 그렇다보니 저는 모듈 사용에 있어서도 무료로 사용할 수 있을 줄 알았습니다.
그런데 유료서버로 전환 이유 웬걸! 돈이 부과가 되고 있었습니다.
그래가지고 저는 고지서를 보자마자 충격을 받고 바로 AWS로 갈아타게 되었습니다..ㅠㅠ
-
AWS로 이전, 더 깊어지는 서버 최적화의 고민

일단 AWS를 선택하게 됨에 있어 얻게되는 이점은 다음과 같습니다.
-
대학 웹메일 인증 시, AWS Credit 100달러 지급 (Credit은 매 달 받는 청구서에서 극 일부 서비스를 제외하고 크레딧으로 대체 가능)
-
서버 사용금액에 있어 한국의 주요 호스팅 서비스와 같이 사전에 서비스를 이용금액을 계약하는게 아닌, 일단 쓰고 나중에 서비스를 사용한 만큼 돈이 부과
-
개발에 필요한 다양한 기술의 AWS 서비스를 사용할 수 있음. (데이터 저장서버, 호스팅 서버, DB서버 등)
-
트래픽, 메모리, 용량 등 서버 스펙이 부족하다 싶으면 유동적으로 늘리거나 줄일 수 있음.
다음으로 이전하게 된 AWS는 과거에도 많이 써왔다 보니 큰 어려움 없이 쓸거라 믿어왔습니다.
일단 AWS에서 역시 최대한 저비용을 고려하여 EC2 서버는 t2.micro 서비스를 이용했습니다.

하지만.. 저스펙의 한계일까요...
AWS EC2에서 서버도 돌리고, 크롤링에 대해 Scheduler Job도 돌릴려 하니까 메모리 부족 문제가 생기게 됩니다..ㅠ

Selenium 크롤링에서 메모리를 많이 쓰이다 보니 발생되는 현상입니다..ㅠ
진짜 저 메모리 부족 문제를 해결할려고 Sidekiq(Queue Background Job) 기법도 써봤지만.. 아무것도 먹히지 않아서 어떻게 해야 할지에 대해 약 2일동안 고민에 빠지게 됩니다..
-
AWS Lamabda의 도입

같이 개발하던 Front-End 형으로부터 람다를 써보는게 어떻냐는 제안을 받게 됩니다.
Catchdeal 소개 (렌더링) 페이지 및 Restful API 통신과 Database를 EC2가 맡고, 데이터베이스를 크롤링 수집하는 CronJob 작업에 대해서만 AWS Lambda를 돌리는쪽으로 기획을 구상하게 됩니다.
하지만 AWS Lamabda에 대해서는 제 개발인생에 있어 처음 도전하는 서비스이다 보니 처음부터 뭘 어떻게 배워야 할지 감이 안잡혔습니다.
더군다나 람다는 작년부터 Ruby 지원이 시작이 되었다 보니, Ruby 기반으로 작성된 AWS Lamabda 관련 자료도 거의 없다싶이 해서 너무 막막했었습니다.

레일즈 개발자 톡방에서도 조언을 구해보는데.. 다양한 답이 나왔습니다.


Ruby + Docker랑 Ruby on Jets라는 서버리스 프레임워크 라는 답을 얻게 되었는데, 저는 이 때 Ruby on Jets라는 웹프레임워크를 그냥 이름에 끌려서(?) 선택하게 되었습니다!
하지만 Ruby on Jets 같은 경우는 살짝 문제가 있었습니다. 한국어 자료가 너무 없다싶이 해서 (공부할 때 당시엔 당근마켓 연사자료 하나가 다였음) 첫 시작에서 살짝 버벅거리긴 했지만.. 다행히도 Rails와 거의 다를 바 없는 프레임워크여서 후에 배울땐 다행히도 잘 배울 수 있었습니다.
더군다나 직접 Ruby on Jets를 개발하신분이 친절하게 영어판으로 Document 자료를 다 만들어주신 덕분에 해당 프레임워크를 큰 틀 선에서 배우는데에도 한 3-5일 밖에 안걸린 것 같습니다.
Ruby on Jets 같은 경우는 AWS Lamabda로 프로젝트 배포에 있어 모든 설정을 자동으로 해주는 정말 매력적인 서버리스 프레임워크였습니다. 그렇다보니 혼자서 노가다를 하면서 설정할 필요 없이, 단순히 명령어 한 줄 만으로 AWS Lambda 내 모든 설정이 자동으로 이루어져서 큰 배움 없이 정말 편리하게 개발을 할 수 있었습니다.
이제 한 3-5일 정도 배우고 난 뒤, 크롤링 작업에 대해 AWS Lambda로 분리를 해서 사용해보니 이제는 EC2 서버에 메모리 부족 없이 쾌적하게 잘 돌아가는것이 확인되었습니다.
그리고 이 좋은건 저만 몰래 알 순 없는법! 마침 한국에 Ruby on Jets 자료도 없다싶이 해가지고 열심히 헤딩해서 알아낸 지식, 알짜베기 지식을 블로그에 작성해냈습니다.
관련 개발지식 연결고리
2. Ruby on Jets : Lambda 스케쥴링 Job
3. Ruby on Jets : AWS Lambda에서 Selenium 크롤링
4. Ruby on Rails : 다른 AWS EC2 서버 내의 Database와 Remote Connect 하기
7. Ruby on Jets : AWS Lambda 배포
또한 AWS Lambda 같은 경우는 24시간 서버가 돌아가는게 아닌, 제가 시간만 정하면 크롤링 작업이 자동적으로 돌아갈 수 있게 하고, 작업이 돌아가는데 할애된 Time/Memory에 대해서만 비용이 부과되는 개념이라 비용적으로서도 너무 친절했습니다!
-
AWS Lambda에 대해 앞으로 풀어나가야 할 과제
1. AWS Lambda 공부 및 효율적인 비용부과 Way
AWS Lambda 같은 경우는 제가 스스로 0부터 셋팅을 해본 경험이 없다 보니, 내부 구조에 대해서도 계속 공부하면서 더 알아가봐야 할 것 같습니다. AWS Lambda에서 자체적으로 제공하는 기능 중, 제가 눈치채지 못한 숨겨진 편리한 기능이 있을 수도 있고, 그 속에서 비용이 어느 부분에서 올라가거나 내려가는지에 대해 공부하는게 최대의 관건 같습니다.

저번 1월달 요금고지서를 보니까 제가 뭣도 모르고 AWS Lambda를 이것저것 만지고, 너무 자주 Job을 돌리는 바람에 엄청난 비용이 나오게 되었습니다..ㅠㅠ (비용은 다행히 Credit으로 대체되었습니다...)
2. Ruby on Jets, 널 더 알고싶어.
Ruby on Jets는 Ruby on Rails와 비슷하면서도 뭔가 다른게 참 많은게, Jets에서 Gem을 설치하면 안돌아가는것도 몇 개 있습니다.
또, Jets에서는 코드가 잘 돌아가지만 AWS Lambda에서는 안돌아가는 코드가 있기도 합니다.
(이것때문에 30분을 고생함..)
@hash = {"user_0"=>{"userId"=>"23", "bookmarkCount"=>6}, "user_1"=>{"userID"=>"42", "bookmarkCount"=>3}}
## Ruby on Jets에서는 정상적으로 돌아가나, AWS Lambda에서는 안돌아감.
@hash.each_with_index do |userData, index|
puts userData["user_#{index}"]
end
## 다음과 같이 수정 시, Ruby on Jets/AWS Lambda 둘 다 정상 작동.
@hash.values.each do |userData|
puts userData["userId"]
end
그리고 계속 파고들면 파고들수록 뭔가 AWS Lambda를 자동으로 쉽게 설정해주는 기능들이 많이 익혀지게 되더라고요. 이런 숨겨진 기능에 대해서도 계속해나아가서 알아봐야 할 것 같습니다!
-
앞으로의 서버 분리 : 더더더 서버분리
Server Ver 1.
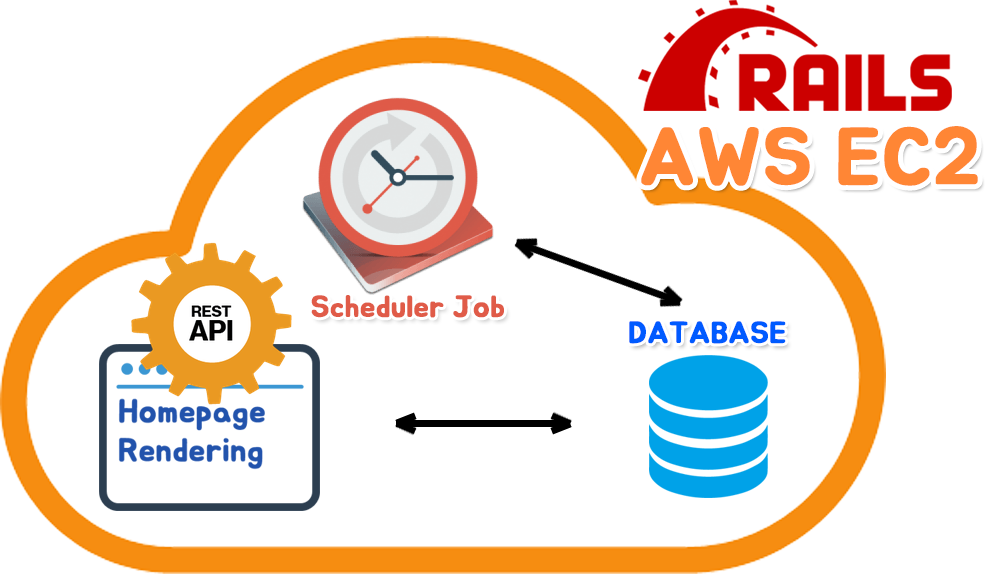
극 초창기에 운용되었던 과거의 서버 운영방식입니다.
처음에는 모든 기능을 AWS EC2에 때려박은 채로 시작되었습니다. (Heroku 시절 또한 동일했습니다.)
하지만 앞서 얘기했다 싶이 Cron Job 활용에 있어 메모리 부족 문제가 발생하게 되어 위와같은 방식은 비효율적이란걸 깨닫게 됩니다.
물론 EC2 서버의 하드웨어 성능(메모리, CPU 등)을 높이면 되긴 하나, 그래도 다른 효율적인 선택지가 있는 현 시점에서는 정말 비효율적입니다.
Server Ver 2.
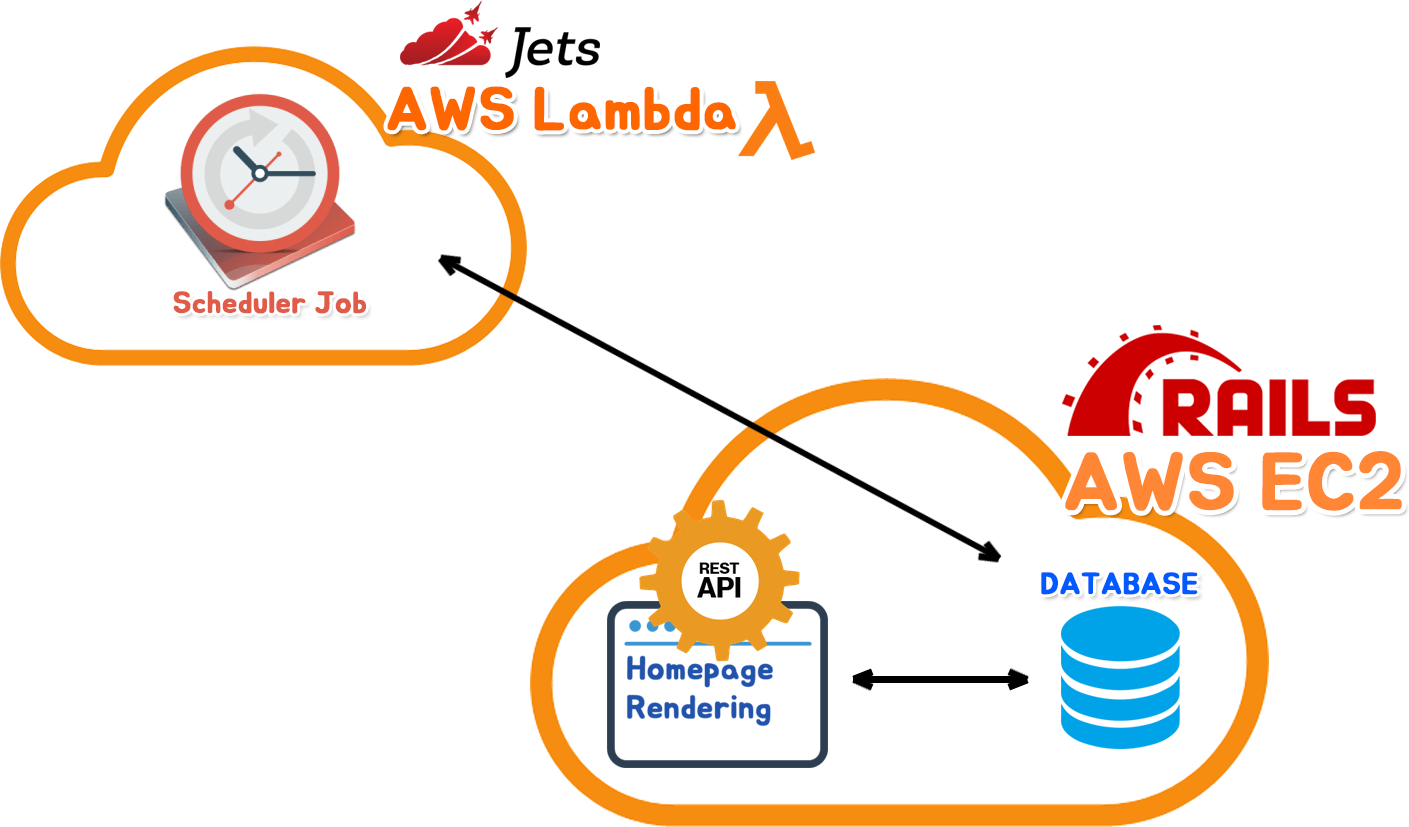
2020. 2. 11 기준 캐치딜의 서버 상태입니다. 위 사진처럼 보시다싶이 스케쥴러+Crawl Job과 Database+웹서버 로 분리되어 운영되고 있습니다.
사실 저는 'AWS Lambda에 Scheduler Job을 돌리면 비용이 많이 절감되겠지!' 하며 써왔다가 오히려 더 많은 과금폭탄을 맞게 되었었습니다. 그 원인은 Selenium을 돌리는 코드였는데, Selenium을 쓰는 크롤러가 Memory를 많이 쓰다보니 메모리 사용량에 대한 비용이 청구가 많이 되는바람에 이는 Heroku의 Scheduler를 쓰는 것 보다 엄청난 과금이 부가가 되었었습니다.
이 때문에 Scheduler Job을 돌리는 서버에 대해 분산화 작업을 했어야 했습니다.
아울러, 서버 과금을 아끼기 위한 자세한 이야기는 다른 글에 자세히 풀어봤으니, 관심있으시면 참고바랍니다 :)
부록 캐치딜 백엔드 개발이야기 : 나에게 맞는 합리적인 서버 비용을 찾아서..
Server Ver 3.
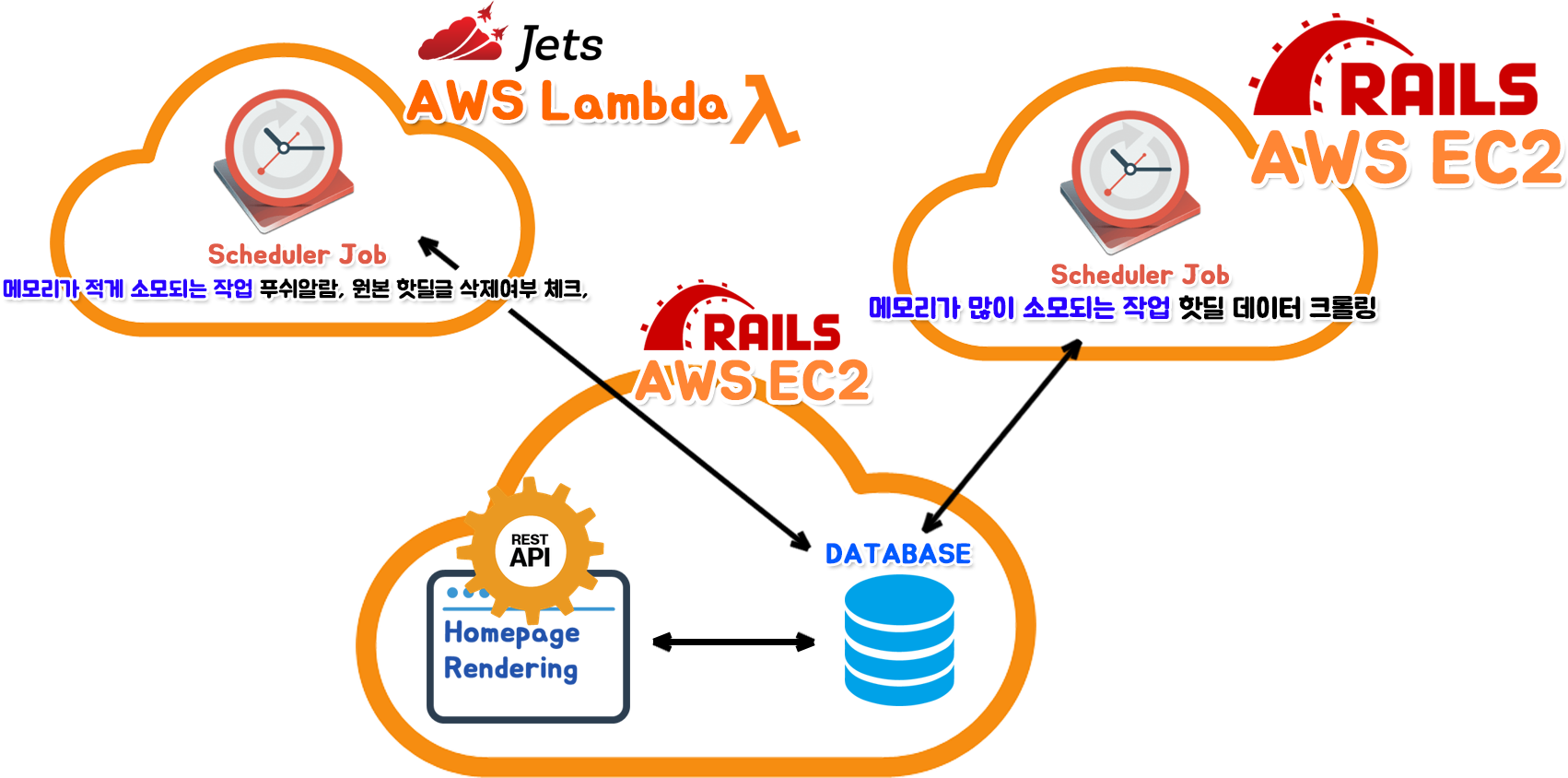
2020년 4월 초 까지의 캐치딜의 서버 상태 였습니다.
생각해보니 AWS Lambda는 '쓴만큼 부과과 되긴 하는데 시간+Memory(유동적)' 에 대해 부과가 되지만, AWS EC2는 '쓴만큼 부과과 되긴 하는데 시간+Memory(고정적)' 으로 과금이 된다는 생각이 스윽 지나가게 됩니다.
위 사진대로 서버 인프라를 재설계하고, 캐치딜을 운영해보니 과거 2버전 때 보다 확실히.. 나았고, 비용도 덜 들었습니다.
Server Ver. 4

현재의 캐치딜의 서버 상태(2020. 4. 11 글 수정 기준) 입니다.
누구나 서버에 요청을 하게 될 시, 빠른 응답을 원합니다.
사실 지금도 괜찮은 반응 속도이긴 하나, 더 빠른 응답속도에 대해 욕심이 생기고, 나중에 유저들이 한번에 서버에 요청을 할 경우 지금 인프라로선 한계가 있을 것 같더라고요..

그렇게 약 4주동안 redis를 공부한 끝에 redis를 DB와 접목시키게 되었고, 서버는 캐싱 후 데이터를 열람 시 더 빠른속도로 반응을 하게 되었습니다. (데이터를 조회하는 ActiveRecord 반응속도를 보면 거의 4배속도로 빠르게 데이터를 보여줍니다!)
부록 Ruby on Rails : 데이터 캐싱 (Redis, Rails Cache 활용)
Server Ver. 5

앞으로 꿈꾸는 서버의 설계입니다.
현재는 REST API와 캐치딜 소개 페이지와 DB가 하나의 AWS EC2에서 사용되고 있지만, 앞으로 규모가 커질 것에 대비한 제 최종 목표는 이를 전부 세세히 세분화 시키는겁니다.
저도 사실 Server Ver. 4 까지 서버 인프라 설계를 해보게 될줄은 몰랐고, 유저도 미세하게 늘어나고 있는 상태이다보니 이제 저도 중/대규모 서비스를 고려한 개발을 계속해서 꿈꿔나가야 할 것 같아요..
이제 Server Ver. 5 인프라 설계가 끝나면, Auto Scaling을 통해 트래픽 분산 작업에 대해서도 꿈꾸고 있습니다.
부록 10만명 유저를 위한 시스템 만들기
-
내부 코드의 효율적인 관리
개인적으로 내부 코드에 대해서도 크게 신경써야 한다고 생각이 됩니다.
그 대표적인 케이스로서는 바로 SQL N+1 입니다.


위 상황은 유저 앞으로 보내진 푸쉬알람 리스트를 조회하는 API 통신 과정입니다.
하지만 좌측 SQL Query를보면.... 정말 불편합니다. 뭔가 쓸데없이 계속 Select 구문이 호출되고 있습니다.
위 현상이 바로 SQL N+1 의 대표적인 예시입니다.
과거에 저도 왜 저렇게 코드를 짰는지 모르겠는데 어느 날 우연히 저렇게 코드를 잘못짰단 것을 확인하게 됩니다.
위와같은 SQL N+1은 테이블 내 데이터가 적을때야 크게 상관은 없을텐데, 만약 데이터가 몇천개, 아니 몇 만개를 조회해야 한다면 위와같은 방식은 너무 비정상적이면서도 과도한 내부 탐색 퍼포먼스로 인해 서버가 다운될 우려가 있습니다.
위와같은 문제에 대한 해결법은 테이블 조인입니다.
부록 Ruby on Rails : Table JOIN
테이블 조인은 2개 이상의 테이블 내 공통점이 있는 에트리뷰트(컬럼)를 기준으로 하여 2개의 이상의 테이블을 하나로 합친 후 결과를 보여주는 방식입니다.
이 방법을 이용하면 위처럼 반복적인 테이블 조회과정 없이 단 한번의 과정으로 조건에 맞는 데이터의 결과를 가져올 수 있습니다.

이제 위 방법을 이용하면 아까는 9.0ms 이상 걸리던 시간이 4.1ms 로 크게 단축됩니다.
이러한 케이스처럼 내부 코드 알고리즘도 크게 신경쓰는것도 하나의 과제입니다.
그리고 더 나아가, Table View에 대해서도 새로이 공부해나가야 할 것 같습니다.
부록
[DB기초] 뷰(View)란 무엇인가? + 간단한 예제
View vs Join
Table View에 있어서도 데이터 탐색속도가 좋다는 얘기를 들어가지고 아직 확정적으로 View를 할지 결정을 하진 않았지만, View VS Join에 대해 좀 더 알아보고, View가 성능에 더 좋을 것 같다 싶으면 해당 부분에 대해서도 고민해봐야 할 것 같습니다.
-
마무리
서버는 정말 민감하면서도 쉽지 않은 친구인 것 같습니다.
일단 어느 플랫폼이 합리적인 가격인지를 알아야하는건 기본이고, 또한 서버 내부에서도 언제 과부화가 될지 모르니.. 항상 경계해야 할 녀석입니다. 그리고 서버가 죽지 않도록 내부코드 역시 효율적으로 설계를 해야하면서도, 서버 아키텍쳐를 설계함에 있어서 현재의 상황(비용, 현재의 트래픽 상황 등)에 고려해서 잘 설계를 해야 하는것도 하나의 과제입니다. (이래서 마이크로서비스 라는게 나왔나 봅니다.)
또한 서버는 컨텐츠의 심장이기도 하니 언제든지 로그를 체크하면서 예의주시를 해야 합니다.
세상은 계속해서 서버의 효율적인 관리를 위해 서버 로그를 집계해주는 Data Dog 같은 툴들도 많이 나오고 있습니다.
후에 있어선 이런 관리툴에 대한 공부도 자세히 해나가야 할 것 같습니다.
-
캐치딜 개발 이야기 연결고리
1. 캐치딜 백엔드 개발이야기 : 좌충우돌 서버 설계 및 운영 이야기
5. 캐치딜 백엔드 개발이야기 : Restful API 설계의 다양한 고민
6. 캐치딜 백엔드 개발이야기 : 나에게 맞는 합리적인 서버 비용을 찾아서..
'개발 포토폴리오 > 캐치딜(백엔드) 개발 이야기' 카테고리의 다른 글
| 캐치딜 백엔드 개발이야기 : 나에게 맞는 합리적인 서버 비용을 찾아서.. (6) | 2020.04.11 |
|---|---|
| 캐치딜 백엔드 개발이야기 : Restful API 설계의 다양한 고민 (2) | 2020.02.05 |
| 캐치딜 백엔드 개발이야기 : 크롤링 (3) | 2020.02.04 |
| 캐치딜 백엔드 개발이야기 : 디자이너와의 협업 (2) | 2020.02.04 |
| 캐치딜 백엔드 개발이야기 : 문서화 (0) | 2020.02.03 |
