
티스토리 뷰
Ruby on Jets : AWS Lambda에서 Selenium 크롤링
나른한 하루 2020. 1. 21. 04:35
사실 크롤링은 꼭 AWS Lambda가 아니더라도 AWS EC2 등 환경에서도 Rails를 통해 작업을 해낼 수 있습니다. 하지만 이번에 개인적인 프로젝트를 하면서 EC2서버에 크롤링을 돌리기에는 높은 스펙의 서버가 필요하고, 서버 유지 비용도 만만치 않을것이라고 여겨졌습니다.
그렇게 눈을 돌리게 된 것이 AWS Lamabda 였습니다.
AWS Lamabda 환경에서 Selenium 크롤링이 이루어지게 하는 법에 대해 다뤄보겠습니다.
-
(시작 전) Why AWS Lambda than EC2 ?
1. 서버비용
AWS EC2에서 크롤링을 돌리기 위해선 24시간 서버를 켜놔야 합니다. 하지만 시간=돈 입니다.
반면에 AWS Lambda 같은 경우는 일단 프리티어가 아니더라도 100만번 작업 내에서는 Lambda를 무료로 사용할 수 있게 합니다.

다음과 같은 경우, AWS Lambda를 사용하는것을 비추천 드려요.
1) Selenium을 통해 빈번하게(약 5분에 1번씩 이를 24시간 내내) 크롤링을 할 경우
Selenium은 Nokokiri와 같은 크롤링 기법에 비해 많은 메모리가 사용되다보니, 프리티어로 지급해주는 400,000GB 메모리를 금방 소진합니다. 이럴경우엔 차라리 AWS EC2를 쓰는게 나을 수 있습니다.
2) 100만번 이상 작업을 할 경우
Lambda는 100만번 이상의 요청을 넘겨버릴 경우, 과금계산이 진행됩니다.
2. 서버의 부담
AWS EC2에서 크롤링을 돌리고 있을 때, EC2 서버 자체에 많은 부담이 갑니다.
특히 t2.micro 스펙에서 크롤링을 돌리면 서버가 바로 뻑나가는걸 겪어봤습니다..
-
Jets 프로젝트 내 작업
이번 프로젝트 실습을 통해 네이버 중고나라 사이트에 게시되는 상품이 크롤러가 데이터를 수집해서 눈으로 직접 확인해보는 작업을 해보겠습니다.
1. 우선 Selenium과 관련된 Gem을 설치해줘야 합니다.
Gemfile 로 이동 후, 다음 2개의 Gem을 입력해주세요.
# selenium 크롤링
gem 'selenium-webdriver'
gem 'chromedriver-helper'그리고 터미널에 다음 명령어를 입력해서 Gem을 설치합니다.
bundle install
2. Job을 하나 개설합니다.
jets g job naver_crawl부록 Jets Job 개념 [클릭]
3. 생성된 Job 파일을 열람 후, 다음과 같이 내용을 채워주세요.
class NaverCrawlJob < ApplicationJob
# rate "10 hours" # every 10 hours
def sample
Selenium::WebDriver::Chrome.driver_path = "/opt/bin/chrome/chromedriver"
## 헤드리스 개념 : https://beomi.github.io/2017/09/28/HowToMakeWebCrawler-Headless-Chrome/
options = Selenium::WebDriver::Chrome::Options.new(binary:"/opt/bin/chrome/headless-chromium")
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
# 셀레니움 + 크롬 + 헤드리스 옵션으로 브라우저 실행
@browser = Selenium::WebDriver.for(:chrome, options: options)
# 다음 페이지로 이동
@browser.navigate().to "https://cafe.naver.com/joonggonara?iframe_url=/ArticleList.nhn%3Fsearch.clubid=10050146%26search.menuid=334%26search.boardtype=L"
# iframe에서 frame 형으로 전환
@browser.switch_to.frame("cafe_main")
## find_element랑 find_elements의 차이를 꼭 알아두자.
# https://stackoverflow.com/a/14425080
@content = @browser.find_elements(css: "#main-area > div:nth-child(7) > table > tbody > tr")
@productList = Array.new
puts "- Naver 중고나라 -"
@content.each do |t|
@title = t.find_element(css: "a.article").text
@nickname = t.find_element(css: "a.m-tcol-c").text
@date = t.find_element(css: "td.td_date").text
@url = t.find_element(tag_name: "a").attribute("href")
@productList << [@title, @nickname, @date, @url]
## 서버 로그 확인용
puts @productList
end
@browser.quit
end
end
4. Deploy 해줍니다.
Environment 환경은 여러분들이 설정한 것에 맞게 해주세요. (저는 Production 환경으로 배포를 해왔습니다.)
# jets deploy [Environment]
# jets deploy production
jets deploy production
-
AWS Lambda Layer Package : Chrome
Deploy 후, 한번 테스트를 해보려 하면 다음과 같은 오류를 겪게 될겁니다.
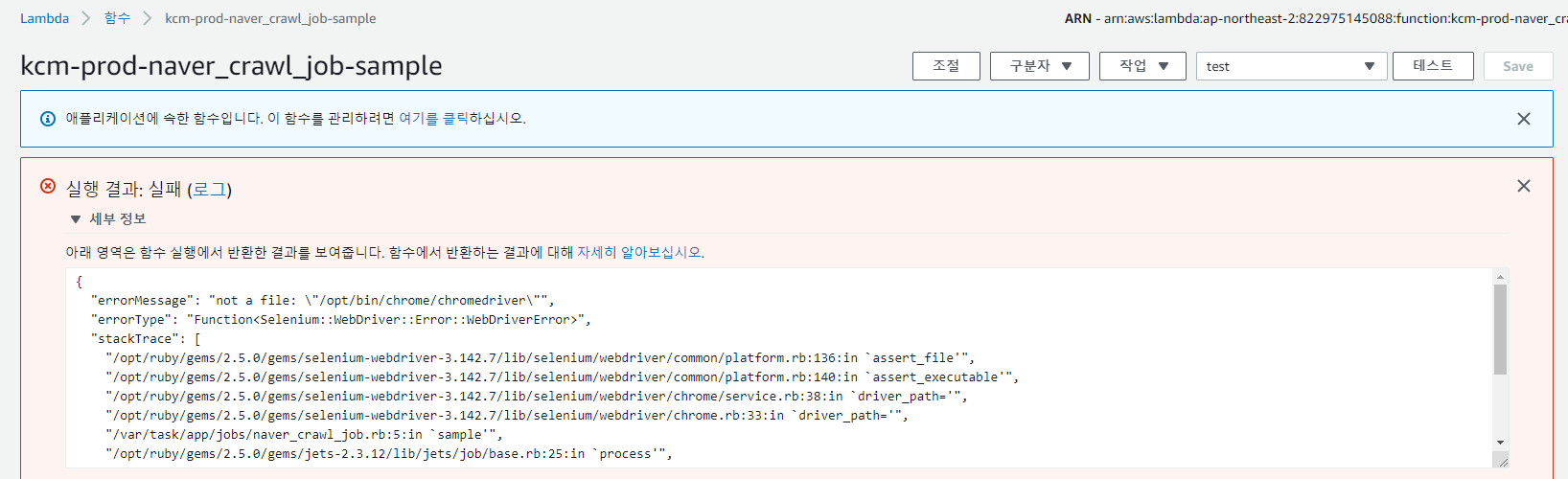
이는 naver_crawl_job.rb 파일 내 코드에 원인이 있습니다.
Selenium::WebDriver::Chrome.driver_path = "/opt/bin/chrome/chromedriver"
options = Selenium::WebDriver::Chrome::Options.new(binary:"/opt/bin/chrome/headless-chromium")위 코드에 보면 크롬 드라이버와 Chrome Binary 파일 위치가 명백하게 표시되어 있습니다.
하지만 Lambda에서는 /opt/bin/chrome 위치에 아무것도 없는 상태입니다.
/opt 이하 위치의 파일은 주로 AWS Lambda의 계층(Layer) 이라 불리는 패키지 관리 기술이 있는데 계층파일들이 /opt 이하 디렉토리에서 관리가 됩니다.
부록 계층(Layer) 개념 및 이해 [클릭]
이제 지금부터 계층(Layer)을 통해 /opt/bin/chrome 위치에 크롬드라이버와 Chrome Binary 파일을 올려보겠습니다.
1. Ruby on Jets(Cloud9)으로 돌아와서, 프로젝트의 루트 위치에서 opt/bin/chrome 디렉터리를 추가합니다.

2. 터미널에서 /opt/bin/chrome 위치로 이동합니다.
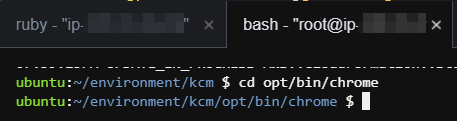
3. Jets 프로젝트 내에 크롬 드라이버 및 Binary 파일을 다운로드 받습니다.
1) 크롬 드라이버 (Version : 2.42, Supports Chrome v68-70)
## 크롬드라이버 패키지 다운로드 및 zip 압축
curl -SL https://chromedriver.storage.googleapis.com/2.42/chromedriver_linux64.zip > chromedriver.zip
## 압축해제
unzip chromedriver.zip
## 압축파일 삭제
rm ./chromedriver.zip2) 크롬 Binary 파일 (Chrome Version : 69.0.3497.81)
## 크롬 다운로드
curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
## 압축해제
unzip headless-chromium.zip
## 압축파일 삭제
rm ./headless-chromium.zip
4. bin 폴더에 우측마우스를 클릭 후, 내 PC로 다운로드를 합니다.
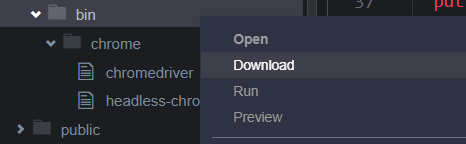
5. Jets 프로젝트 내에 아까 만들어냈던 opt 이하 디렉터리들을 다 삭제하세요.
6. AWS Lambda 페이지로 이동합니다.
7. 좌측메뉴를 보면 계층 이라고 보일겁니다.
계층을 클릭해주세요.

8. 이어서 계층 생성 을 클릭해주세요.

9. 아까 Jets 프로젝트에서 다운받았던 파일(bin 폴더 및 Chrome 파일들)의 zip 파일을 업로드해주세요.
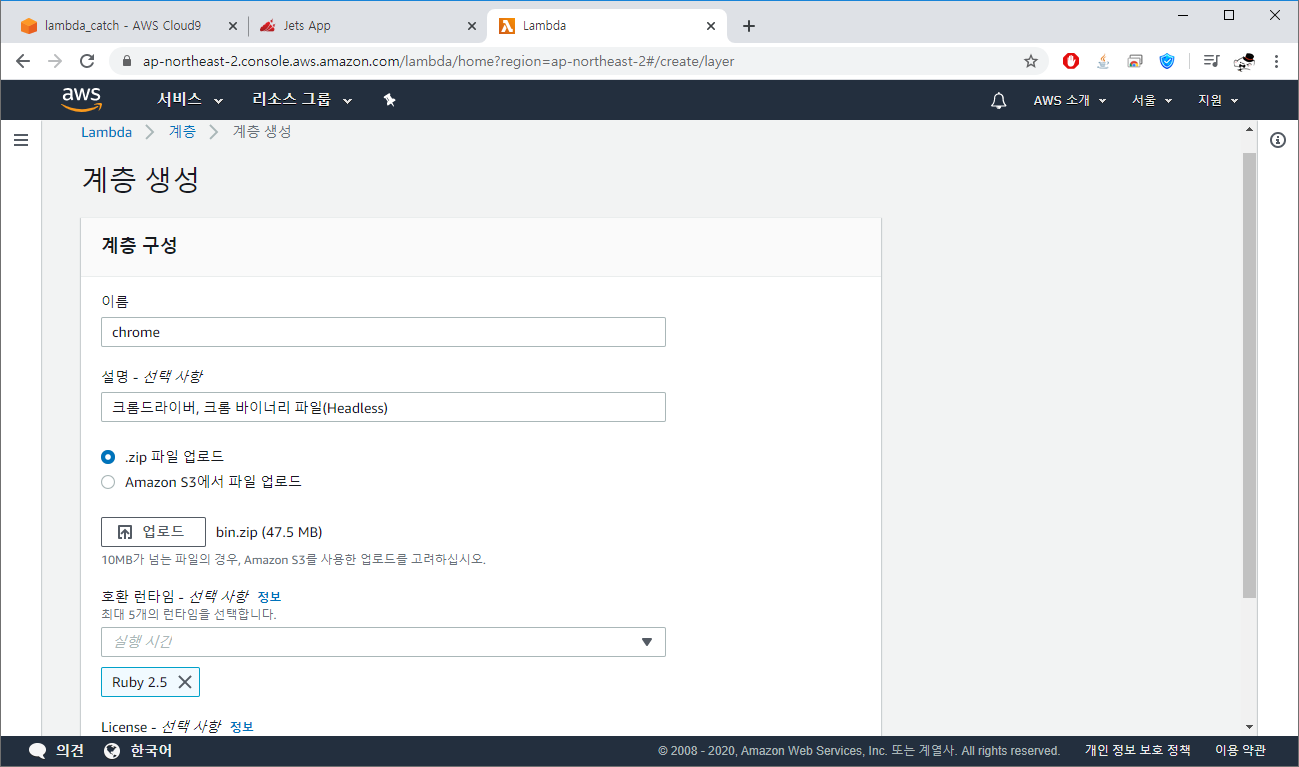
이름 및 설명은 자유롭게 작성해도 되나, 호환 런타임은 Ruby 2.5 로 설정해주세요.
업로드 및 계층 추가까지 약 30초 정도 걸립니다.
참고1 업로드 파일 용량은 50MB가 넘어선 안됩니다.
참고2 계층에 업로드 되는 파일들은 opt 파일에 저장됩니다.
10. Lambda 함수 목록 페이지로 이동합니다.
11. 초반에 만들었던 Job 파일이 있는 함수로 이동합니다.

12. 함수 페이지로 이동 후, Layers 를 클릭합니다. 그러면 하단에 계층(Layer)들이 보여지는데,
여기서 Add a layer 을 클릭합니다.

13. 8번 과정 때 생성해냈던 계층을 추가합니다.

14. Layer을 추가하면 다시 함수의 메인페이지로 이동이 되는데 Save 버튼을 눌러서 함수의 레이어/코드 최신화를 합니다.
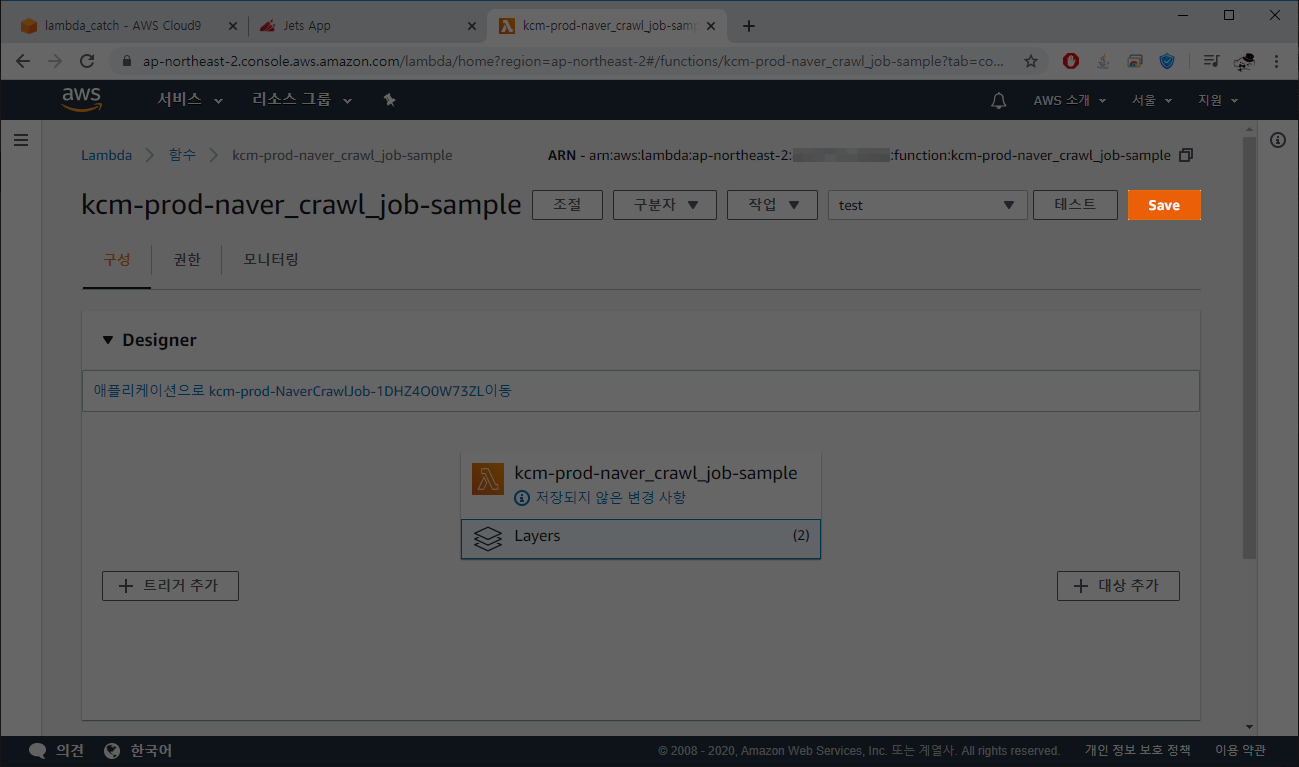
Save 까지 보통 약 40초 정도 걸립니다.
15. 함수 최신화 후, 테스트 버튼을 눌러서 이제 크롤링이 잘 되는지 확인해봅니다!

16. 크롤링이 무사히 잘 이뤄진게 확인이 됩니다!

-
Selenium을 활용한 개발 유의사항
1. webdrivers Gem을 쓰지 마세요.
webdrivers Gem을 쓰게 되면 다음 에러를 겪게 됩니다.
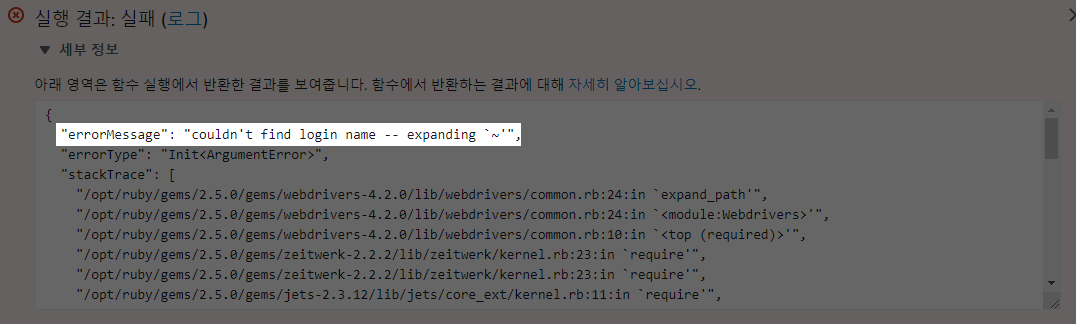
해당 에러는 여전히 Github, Stackoverflow에서 이슈화만 되고있지, 해결방법은 여전히 안나온 상태입니다.
2. Jets 프로젝트에 chromedriver 및 Chrome binary 파일을 함께 Deploy 하지마세요.
Jets 프로젝트 용량이 너무 크게 되면 코드 열람이 안됩니다.
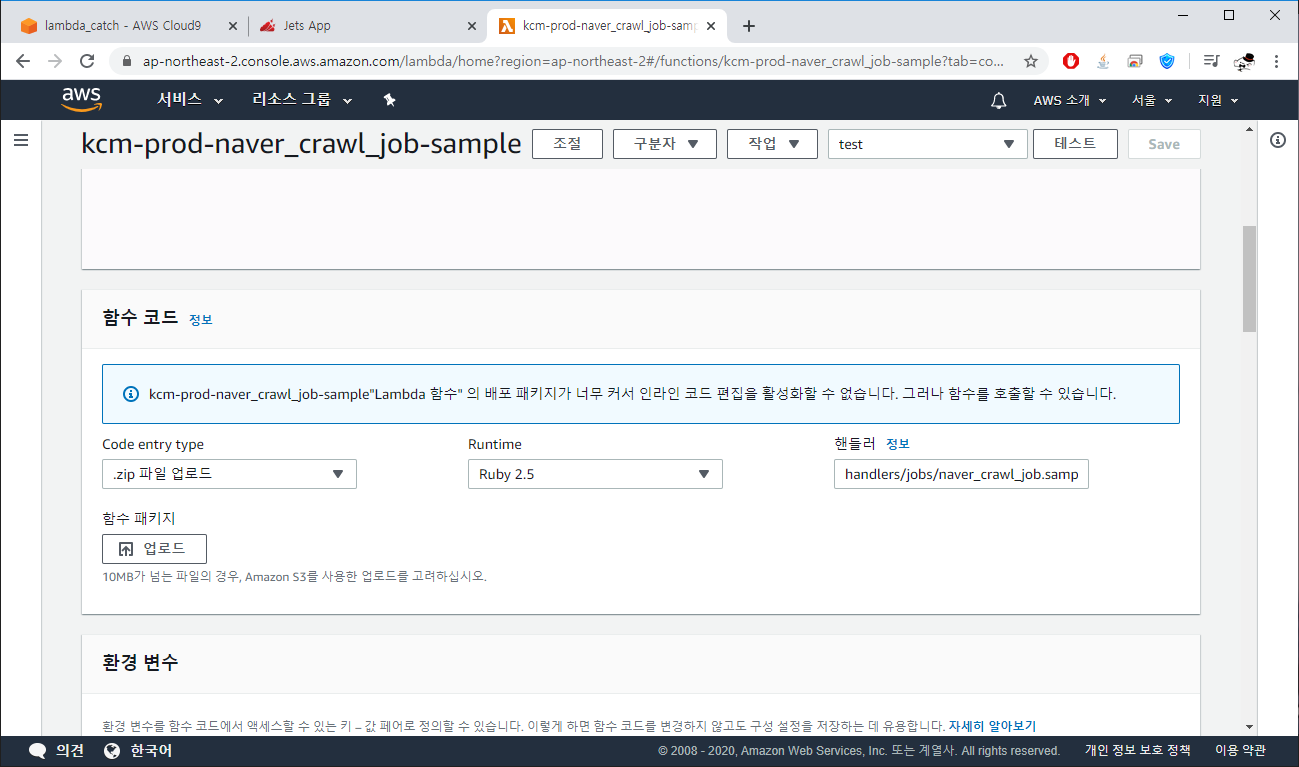
-
관련 자료
1. AWS Lambda Layer Document [클릭]
-
자료 참고
1. Chromedriver 자료실 [클릭]
2. Chrome Binary 자료실 [클릭]
3. Chrome Binary 및 chromedriver 버전 호환 문제 [클릭]
4. AWS Lambda에서 Ruby를 활용한 Bot 생성 [클릭]
5. Chrome 패키지 설치 [클릭]
6. AWS Lamabda Selenium에 최적화된 Chrome add_argument 옵션 [클릭]
'프로그래밍 공부 > Ruby on Jets : 서버리스 프레임워크' 카테고리의 다른 글
| Ruby on Jets : 환경변수 등록 (0) | 2020.01.23 |
|---|---|
| AWS Lambda : 계층(Layer)의 이해 (2) | 2020.01.21 |
| Ruby on Jets : AWS Lambda Project 제거 (0) | 2020.01.21 |
| Ruby on Jets : Lambda 스케쥴링 Job (0) | 2020.01.20 |
| Ruby on Jets : AWS Lambda 배포 (0) | 2020.01.20 |
