
티스토리 뷰
데이터베이스를 다룸에 있어, 때로는 2개 이상의 테이블을 하나로 합친 후, 공통된 데이터에 대해 빠른 탐색 처리를 해야할 필요가 있습니다.
이번 설명은 상황을 하나 제시하여 설명을 하겠습니다.
상황
예를들어 아래와 같은 테이블 설계가 되어있다고 치겠습니다.
hit_products 모든 특가 상품 데이터

book_marks 유저(user)가 어떤 특가 상품(hit_products)에 대해 북마크를 했는지에 대한 데이터
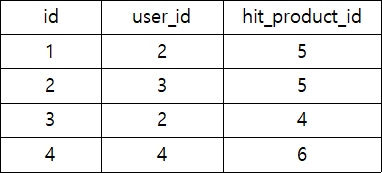
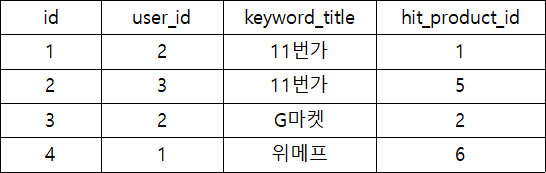
keyword_pushalarm_list 유저(user)가 등록한 키워드를 기반으로 받은 핫딜 정보에 대한 푸쉬알람
1. 개발자는 hit_product 테이블 내 데이터 중, 현재(2020년 1월 31일)를 기준으로 하여 작성된지 30일이 지난 데이터를 자동으로 삭제하는 코드를 구현하려 합니다.
## SQL
SELECT * FROM hit_products WHERE(hit_products.created_at < '2019-12-31')
## ORM : Ruby on Rails
class ManageDeleteArticle < ApplicationJob
def hit_products_delete
HitProduct.where('hit_products.created_at < ?', 30.days.ago).each do |product|
product.destroy
end
end
def main
hit_products_delete
end
end
2020년 1월 31일 기준, 삭제되어야 되는 대상은 다음과 같습니다.

2. 하지만 삭제가 됨에 있어서 hit_products 데이터가 하나라도 북마크(book_marks) 혹은 키워드 푸쉬알람(keyword_pushalarm_list)에 있는 경우, 60일 뒤에 삭제되어야 하는 규칙이 있습니다.
이 규칙을 다시 적용하여 코드를 짜보면 다음과 같이 나옵니다.
## SQL
SELECT * FROM book_marks WHERE(book_marks.created_at < now() - INTERVAL '60 DAYS')
SELECT * FROM keyword_pushalarm_lists WHERE(keyword_pushalarm_lists.created_at < now() - INTERVAL '60 DAYS')
SELECT * FROM hit_products WHERE(hit_products.created_at < now() - INTERVAL '30 DAYS');
## ORM : Ruby on Rails
class ManageDeleteArticle < ApplicationJob
def hit_products_delete
HitProduct.where('hit_products.created_at < ?', 30.days.ago).each do |product|
product.destroy
end
end
def book_marks_delete
BookMark.where('created_at < ?', 60.days.ago).each do |x|
x.destroy
end
end
def keyword_pushalarm_list_delete
KeywordPushalarmList.where('created_at < ?', 60.days.ago).each do |x|
x.destroy
end
end
def main
book_marks_delete
keyword_pushalarm_list_delete
hit_products_delete
end
end
3. 1번과 2번 규칙을 종합해보면 다음과 같습니다.
1) 아래 데이터는 2020년 1월 31일 기준 30일 이전의 데이터이지만 삭제가 될 수 없습니다.
* 사유 : keyword_pushalarm_lists 테이블에 등록되어 있는 상태 (60일동안 자료 보존)

2) 아래의 데이터는 book_marks 테이블에 등록되어 있음에도 불구하고, 60일이 지난 관계로 2020년 1월 31일에 삭제를 할 수 있습니다.
* book_marks에 기록되어 있는 1번 데이터(book_marks.id = 1)는 이미 삭제가 되어 있는 상태

3) 아래의 데이터는 book_marks, keyword_pushalarm_lists 테이블 어디에서도 등록되어 있지 않아 2020년 1월 31일에 바로 삭제처리가 됩니다.

4. 최종적으로 봤을 때, hit_products 데이터 삭제에 있어 개발자는 무작정 다음과 같이 코드를 짜서는 안됩니다.
따로 북마크(book_marks) 혹은 키워드 푸쉬알람(keyword_pushalarm_list)에 데이터가 있는지 검사하는 검증 코드가 없어서 미래에 뭔 일이 터질지 모릅니다.
* 아래 코드는 북마크/푸쉬알람 리스트와 상관없이, 30일이 지난 모든 데이터를 삭제처리
## 나쁜 예시
## SQL
(SQL 코드 생략)
SELECT * FROM hit_products WHERE(hit_products.created_at < now() - INTERVAL '30 DAYS');
## ORM : Ruby on Rails
class ManageDeleteArticle < ApplicationJob
(코드 생략)
def hit_products_delete
HitProduct.where('hit_products.created_at < ?', 30.days.ago).each do |product|
product.destroy
end
end
(코드 생략)
end위와같은 상황을 미루어 봤을 때, 저희는 hit_products에서 30일 주기로 삭제가 되는
알고리즘 작성에 있어 book_marks, keyword_pushalarm_lists 테이블에 데이터가 있는지에 대한 검사 및 60일이 지난 데이터 삭제는 아주 간단하게 다음과 같은 방법을 구상을 해볼 수 있습니다.
class ManageDeleteArticle < ApplicationJob
(코드 생략)
def hit_products_delete
HitProduct.all.each do |product|
## 북마크 혹은 푸쉬알람에 데이터가 등록되어 있는지 확인 (false : 등록이 안되어 있음.)
productConditionCheck = false
## 북마크가 등록된지 60일이 지난 데이터 중, 푸쉬알람이 이루어진지 60일이 지난 데이터 삭제
## 푸쉬알람 등록 : 65일 전, 북마크 등록 : 25일 전 데이터가 삭제 안될 수 있는 상황을 대비
BookMark.where('book_marks.created_at < ?', 60.days.ago) |bookmark|
if bookmark.hit_product_id == product.id
productConditionCheck = true
end
KeywordPushalarmList.where('keyword_pushalarm_lists.created_at < ?', 60.days.ago) |pushlist|
if pushlist.hit_product_id == product.id
productConditionCheck = true
end
end
end
## 푸쉬알람이 이루어진지 60일이 지난 데이터 중, 북마크가 등록된지 60일이 지난 데이터 삭제
## 푸쉬알람 등록 : 25일 전, 북마크 등록 : 70일 전 데이터가 삭제 안될 수 있는 상황을 대비
KeywordPushalarmList.where('keyword_pushalarm_lists.created_at < ?', 60.days.ago) |pushlist|
if pushlist.hit_product_id == product.id
productConditionCheck = true
end
BookMark.where('book_marks.created_at < ?', 60.days.ago) |bookmark|
if bookmark.hit_product_id == product.id
productConditionCheck = true
end
end
end
## 북마크 혹은 푸쉬알람에 데이터가 등록되어 있는지 재체크 (true일 경우 삭제)
if productConditionCheck == true
product.delete
end
end
end
(코드 생략)
end
하지만 위 코드는 너무 비효율적입니다
반복문 속에 또 반복문, 또 그 반복문 속에 반복문... 즉 시간복잡도 성을 봤을 때 O(n³) 라는 효율이 전혀 없는 알고리즘입니다.
그리고 코드가 너무 길어서 뭔소린지도 모르겠습니다.
위와같이 코드의 복잡성을 줄이고, 데이터의 빠른 탐색을 위해 필요한 것이 JOIN 입니다.
-
JOIN
2개 이상의 테이블에 대해 하나로 합친 후, 하나로 합쳐진 데이터를 기반으로 자료를 탐색하는데 사용됩니다.
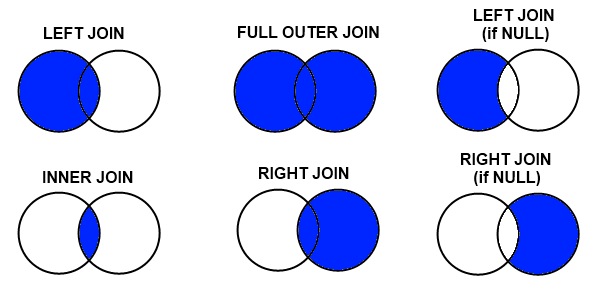
JOIN은 하나의 테이블을 기준점 삼아서 위와같이 여러 기법으로 합친 후, 데이터를 탐색할 수 있습니다.
1. JOIN 기본적인 활용법
JOIN의 기본적인 활용법은 두 개 이상의 테이블에 있어 공통된 Attribute(Column)을 엮어내는 겁니다.
## SQL
SELECT hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title FROM hit_products
LEFT OUTER JOIN book_marks ON hit_products.id = book_marks.hit_product_id;
## ORM : Ruby on Rails
HitProduct.select("hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title").left_joins(:book_marks)위 코드에서 2번째 줄을 보면 두 테이블의 관계에 있어 공통적인 컬럼인 hit_product의 id 값을 기반으로 조인을 하고 있습니다.
-
대표적인 Join 기법 소개
JOIN 결과 데이터들은 다음 테이블의 데이터를 참고해주세요.


1. LEFT (OUTER) JOIN
보통 많이 쓰이는 조인 기법으로서, 왼쪽 테이블을 기준으로 오른쪽 테이블의 부가정보가 추가되는 조인입니다.

## [SQL] hit_products 테이블이 기준이 된 경우
SELECT hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title FROM hit_products
LEFT OUTER JOIN book_marks ON hit_products.id = book_marks.hit_product_id;
## [ORM] hit_products 테이블이 기준이 된 경우
HitProduct.select("hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title").left_joins(:book_marks)## [SQL] book_marks 테이블이 기준이 된 경우
SELECT hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title FROM book_marks
LEFT OUTER JOIN hit_products ON hit_products.id = book_marks.hit_product_id;
## [Ruby on Rails ORM] book_marks 테이블이 기준이 된 경우
BookMark.select("hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title").left_joins(:hit_products)

2. INNER JOIN
두 테이블을 합친 후, 공통적으로 있는 데이터만 보여집니다.
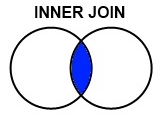
## SQL
SELECT hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title FROM book_marks
INNER JOIN hit_products ON hit_products.id = book_marks.hit_product_id;
## ORM : Ruby on Rails
BookMark.select("hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title").joins(:hit_products)
3. FULL OUT JOIN
두 테이블을 합친 후, 보여지는 모든 경우의 수에 따른 결과를 보여줍니다.

## SQL
SELECT hit_products.id hit_product_id, book_marks.id book_mark_id, hit_products.title FROM book_marks
FULL OUTER JOIN hit_products ON hit_products.id = book_marks.hit_product_id;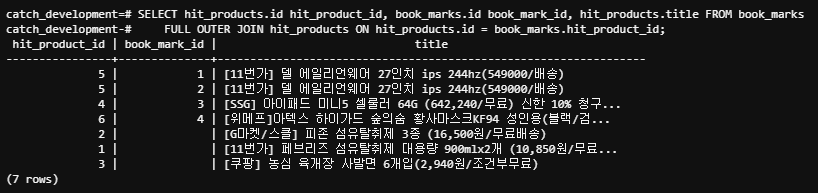
-
LEFT JOIN = LEFT OUTER JOIN ?
Ruby on Rails 같은 경우 레일즈에서 지원되는 LEFT JOIN 메소드를 통해 JOIN 시, 자동으로 LEFT OUTER JOIN으로 정의되어 표현이 됩니다.

하지만 이는 서로 다른 표현이 아닙니다.

Quora 커뮤니티에서도 해당 부분에 대해 이와같은 의문을 가진 사람이 질문을 했었는데,
OUTER의 유무 상관없이 동일하다는 결론이 지어졌습니다.
-
그래서 처음에 예시로 주어진 상황에 대한 해답은??
처음에 주어진 상황 같은 경우는 3개의 테이블을 이용해서 조인 후, book_marks, keyword_pushalarms_lists 어느 테이블에도 존재하지 않는 데이터를 전부 탐색해내면 됩니다.
## SQL
SELECT * FROM book_marks WHERE(book_marks.created_at < now() - INTERVAL '60 DAYS')
SELECT * FROM keyword_pushalarm_lists WHERE(keyword_pushalarm_lists.created_at < now() - INTERVAL '60 DAYS')
SELECT * FROM hit_products A
LEFT OUTER JOIN book_marks B ON A.id = B.hit_product_id
LEFT OUTER JOIN keyword_pushalarm_lists C ON A.id = C.hit_product_id
WHERE B.id is NULL AND C.id is NULL AND A.created_at < now() - INTERVAL '30 DAYS';
## ORM : Ruby on Rails
class ManageDeleteArticle < ApplicationJob
def hit_products_delete
HitProduct.left_joins(:book_marks).left_joins(:keyword_pushalarm_lists).where("book_marks.id is NULL AND keyword_pushalarm_lists.id is NULL").where('hit_products.created_at < ?', 30.days.ago).each do |product|
product.destroy
end
end
def book_marks_delete
BookMark.where('created_at < ?', 60.days.ago).each do |x|
x.destroy
end
end
def keyword_pushalarm_list_delete
KeywordPushalarmList.where('created_at < ?', 60.days.ago).each do |x|
x.destroy
end
end
def main
book_marks_delete
keyword_pushalarm_list_delete
hit_products_delete
end
end
-
조인만으로 테이블 퍼포먼스가 해결될까?
꼭 그렇진 않습니다.
테이블 검색 성능을 향상을 시키기 위해선 색인(Index) 이라는 기능을 도입하는게 좋습니다.

색인은 Original Table의 Key-Value 를 가지고 있는 별도의 테이블이며, Key를 받아내면, Key에 매칭되는 Value값을 추적해내어 테이블 내 데이터 검색 속도를 높입니다.
' 오 그러면 모든 테이블마다 색인을 적용하면 되겠네! '
위 생각같이 저희 뜻대로 이루어지면 좋겠지만.. 융통성 없이 모든 테이블에 이런 짓을 행해서는 안됩니다.
-
장점 색인은 테이블 내 데이터 탐색 속도를 높인다는 장점이 있습니다.
-
장점 색인은 JOIN이 자주 쓰이는 작업에 쓰이는게 좋습니다.
-
단점 테이블 내 내용이 삽입(INSERT)/수정(UPDATE)가 될 경우 삽입(INSERT)/수정(UPDATE) 에 대해 Indexing 함에 있어서 성능이 떨어질 수 있다는 문제점이 발생합니다.
-
단점 데이터 변경 작업이 너무 잦다면 오버헤드 이슈 때문에 오히려 색인(INDEX)을 안쓰는게 나을 수 있습니다.
-
단점 인덱스도 결국 데이터다보니 DB 내 공간을 사용합니다.
-
단점 색인(INDEX)은 테이블 내 데이터가 많을 때 그 힘이 발휘되나, 데이터 양이 너무 적으면 오히려 성능이 떨어집니다.
-
2개 이상의 테이블을 참조함에 있어 조인 처리를 안하면?

SQL N+1 이라는 문제를 겪게되는데, 이게 테이블 내 데이터 탐색에 있어 매우 치명적입니다.
부록 Ruby on Rails : SQL N+1 맛보기
-
자료 참고
1. 다양한 조인 개념 [클릭]
2. 제타위키 : 조인 [클릭]
3. Quora : LEFT JOIN, LEFT OUTER JOIN Difference [클릭]
'프로그래밍 공부 > Ruby on Rails : 이론' 카테고리의 다른 글
| Ruby on Rails : Credentials (0) | 2020.04.17 |
|---|---|
| Ruby on Rails : 로그 (0) | 2020.04.09 |
| Ruby on Rails : 다른 AWS EC2 서버 내의 Database와 Remote Connect 하기 (0) | 2020.01.19 |
| 검색 기능 구현의 고민 : 공백처리 (1) | 2019.12.14 |
| SQLite, PostgreSQL 차이 : Like / iLike (2) | 2019.12.13 |
