
티스토리 뷰
Ruby on Rails : 가상 브라우저를 활용한 크롤링 [Gem : selenium-webdriver]
나른한 하루 2019. 12. 5. 11:52해당 글은 https://blog.naver.com/kbs4674/221220959692 로 부터 게시글이 이전되었습니다.
- 크롤링 자료 연결고리
1. Nokogiri를 활용한 크롤링 [클릭]
- iframe/javascript 기반 사이트에 대해선 크롤링 지원이 안됩니다.
- selenium에 비해 크롤러가 가볍습니다.
2. Selenium을 활용한 크롤링 [클릭]
- iframe/javascript 기반 사이트에 대해선 크롤링 지원이 됩니다.
- Nokogiri에 비해 크롤러가 무겁습니다.
- 크롬 브라우저에 의존합니다. (크롬 브라우저 버전에 신경써야 합니다.)
3. Mechanize를 활용한 크롤링 (Nokogiri + 로그인 기능) [클릭]
- Nokogiri에 로그인 기능이 더해진 크롤러 입니다.
- 개인적으로 대체수단(Selenium)이 있는 만큼, 추천드리진 않습니다.
주의사항
크롤링 시 저작권을 잘 따져가면서 하세요!
웹툰, 구직사이트 등의 크롤링은 특히나 주의하셔야 합니다.
사례 사람인에서 잡코리아 크롤링 하다 소송걸린 사례
크롤링에 있어 최소 홈페이지별로 웹수집 봇에게 정보수집을 명시하는 robots.txt에 명시된 규칙을 지켜가며 할 것을 추천드립니다.
예시 티몬의 robots.txt
- 크롤링이란
크롤링이란, 타 사이트에 있는 자료를 수집하는것을 뜻합니다.
예를들면 저같은 경우는 대학 커뮤니티를 기획했는데, 대학 커뮤니티이다 보니 학생들에게 도움이 되는 정보를 제공하고자
학교에 올려져 있는 공지사항, 학식 정보 등을 긁어와서 제공을 해줍니다.

과거에는 기본적으로 사용되어왔던 Nokogiri, 크롤링에 있어 로그인을 거쳐야 하는 경우 Nokogiri + Mechanize를 이용했어야 했습니다. 하지만 이 부분에 단점이 있었던게
1) 크롤링을 하고자 하는 사이트가 iframe으로 덮여있는 경우, 사용이 제한된다.
* 네이버 카페, 다음 카페 등
2) 크롤링을 하고자 하는 사이트가 사이트 접속 시 javascript를 통해 데이터를 불러온 후, 렌더링을 한다.
* 에브리타임, facebook 등
위 2가지 중 하나라도 걸리면 기존의 Nokogiri 방법으로서는 크롤링이 힘들었습니다.
이번 시간에는 위의 문제를 해결해주면서, Nokogiri+Mechanize의 기능을 가진 Selenium Gem을 소개하겠습니다.
- Gem 소개 : Selenium
Selenium은 가상 브라우저를 이용해서 크롤링을 진행합니다.
보통 GUI 환경의 OS에서는 직접 인터넷창을 띄워서 행동이 이루어지나, CLI 환경으로 이루어진 OS(리눅스, 우분투 등) 같은 경우에는 인터넷 창을 띄우는 것 자체가 제한이 되다보니 이를 위해 나온게 '헤드리스(Headless) 개념입니다.
Headless를 통해서 실제로 브라우저 창을 띈 것과 같이 인터넷창을 이용할 수 있도록 할 수 있습니다.
- Chapter 1 Gem 실습 준비
1. Gemfile 로 이동 후, 2개의 Gem을 설치합니다.
## Gemfile
gem 'chromedriver-helper'
gem 'selenium-webdriver'
그런데 Gem 설치 도중 Test Group 이나 Development Group 부분의 코드를 보면
## Gemfile
...(내용 생략)...
group :test do
# Adds support for Capybara system testing and selenium driver
gem 'capybara', '>= 2.15'
gem 'selenium-webdriver'
# Easy installation and use of chromedriver to run system tests with Chrome
gem 'chromedriver-helper'
end일부 설치해야 하는 Gem이 위와같이 되어있습니다.
여기서 저희가 설치해야 하는 Gem에 대해선 Environment Group 바깥으로 옮겨주세요.
## Gemfile
...(내용 생략)...
group :test do
# Adds support for Capybara system testing and selenium driver
gem 'capybara', '>= 2.15'
end
gem 'selenium-webdriver'
gem 'chromedriver-helper'
...(내용 생략)...
2. Chorome 브라우저를 제어하기 위해 크롬드라이버를 자신의 OS 환경에 맞는 조건에서 설치합니다.
OS : Ubuntu EC2, Cloud9, 구름 IDE 등
sudo apt-get update
sudo apt-get install -y chromium-browser chromium-chromedriver
Ubuntu 기반에서 Chrome을 설치 후, Chrome이 잘 설치되었는지 다음 명령어를 통해 확인합니다.
chromedriver -version
=> ChromeDriver 81.0.4044.138 (8c6c7ba89cc9453625af54f11fd83179e23450fa-refs/branch-heads/4044@{#999})
3. 크롤링을 하고자 하는 메뉴에 마우스를 올리고, 마우스 가운데 버튼을 클릭해서 들어갑니다.
4. 새로운 홈페이지 창이 열린게 확인이 될텐데, 현재 홈페이지 주소가 아래와 같이 잘 나오는지 '그냥 확인만' 합니다.
* 홈페이지 창을 닫진 마세요.
5. Home 라는 이름을 가진 Controller을 생성합니다.
rails g controller homes index
6. Market 이라는 이름을 가진 Model을 생성합니다.
rails g model market title nickname date content:text url이어서 DB를 업데이트 해줍니다.
rake db:migrate
7. lib/tasks 파일을 생성합니다.
참고 lib/tasks 개념 [클릭]
rails g task crawl example
- Chapter 2 Gem 실습 : iframe으로 이루어진 네이버 카페를 직접 크롤링 하기
참고 해당 실습 으로서는 네이버 카페 글을 가져오는 것을 예시로 하겠습니다.
실습 전 유의사항
Step 1 과정이 완료되어 있어야 합니다.
1. lib/tasks/crawl.rb 파일에 다음 내용을 복사/붙여넣기 합니다.
namespace :crawl do
desc "TODO"
task example: :environment do
require "selenium-webdriver"
Selenium::WebDriver::Chrome.driver_path = "/usr/lib/chromium-browser/chromedriver"
## 헤드리스 개념 : https://beomi.github.io/2017/09/28/HowToMakeWebCrawler-Headless-Chrome/
options = Selenium::WebDriver::Chrome::Options.new # 크롬 헤드리스 모드 위해 옵션 설정
options.add_argument('--disable-extensions')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
# 셀레니움 + 크롬 + 헤드리스 옵션으로 브라우저 실행
@browser = Selenium::WebDriver.for :chrome, options: options
# 다음 페이지로 이동
@browser.navigate().to "https://cafe.naver.com/joonggonara?iframe_url=/ArticleList.nhn%3Fsearch.clubid=10050146%26search.menuid=334%26search.boardtype=L"
# iframe에서 frame 형으로 전환
@browser.switch_to.frame("cafe_main")
## find_element랑 find_elements의 차이를 꼭 알아두자.
# https://stackoverflow.com/a/14425080
@content = @browser.find_elements(css: "#main-area > div > table > tbody > tr")
@content.each do |t|
@title = t.find_element(css: "a.article").text
@nickname = t.find_element(css: "a.m-tcol-c").text
@date = t.find_element(css: "td.td_date").text
@url = t.find_element(tag_name: "a").attribute("href")
## 서버 로그 확인용
# puts "제목 : #{@title} / 닉네임 : #{@nickname} / 작성기간 : #{@date} / URL : #{@url}"
Market.create(title: @title, nickname: @nickname, date: @date, url: @url)
end
@browser.quit
end
end참고 크롤링을 하고자 하는 네이버 카페 주소를 바꾸고 싶으시면 17번 째 줄 큰 따옴표 내 URL을 수정해주세요.
< 코드 리뷰 >
1) switch_to.frame
@browser.switch_to.frame("cafe_main")iframe을 frame 형식으로 바꿔줌으로서, 크롤링을 가능하게 합니다.
괄호 안에 들어가는 인자는 iframe name 입니다.
2) CSS 경로는 크롬 브라우저에서 우측마우스를 누르면 보이는 '검사' 기능을 통해 확인이 가능합니다.
조금 더 자세한 CSS 선택자 위치를 구하길 원하시면, 위와같이 검사 로 이동 후,
CSS 선택자 위치를 알아내고자 하는 태그에 우측마우스를 클릭 후, Copy Selector 을 클릭하면 됩니다.
사실 위 방법대로 CSS 선택자 위치를 추출해내면
#main-area > div:nth-child(7) > table > tbody > tr:nth-child(1) > td.td_article > div.board-list > div > a이러한 결과나옵니다만, 이는 딱 하나의 게시글에 대한 정보만 알려주다보니 저희는 모든 게시글에 대한 정보를 수집해야 할 필요가 있어서
#main-area > div:nth-child(7) > table > tbody > tr다음과 같이 수정했습니다.
3) #main-area > div:nth-child(7) > table > tbody > tr 는 게시글 목록 한 줄 전체에 대한 정보를 가지고 있습니다.
이 패턴을 이용해서 각 줄마다의 모든 정보를 수집해냅니다.
@content = @browser.find_elements(css: "#main-area > div:nth-child(7) > table > tbody > tr")참고 크롤링 위치를 가리킬 때 CSS 선택자 외에도 xpath도 지원합니다.
4) find_elements / find_element
- find_elements : 크롤링으로 가져온 데이터 중, 하나만 가지고 있습니다.
- find_element : 여러 개의 데이터 정보를 가지고 있으며, 하나로 뭉쳐친 데이터에 대해 각각의 결과는 each do 문법을 통해 확인합니다.
2. app/controller/homes_controller.rb 로 이동 후, 다음 내용을 입력합니다.
class HomesController < ApplicationController
def index
@data_list = Market.all
end
end
3. app/model/market.rb 파일을 열람 후, 데이터의 중복저장을 막기위해 다음 내용을 작성합니다.
class Market < ApplicationRecord
validates_uniqueness_of :title
end
4. app/views/homes/index.html.erb 에 다음 내용을 입력합니다.
<% @data_list.each do |t| %>
<div><%= t.title %> | 작성자 : <%= t.nickname %> | 등록 : <%= t.date %> <%= link_to "[이동]", t.url, target: "_blank" %></div>
<hr/>
<% end %>
5. 다음 명령어를 통해 lib/tasks/crawl.rb 파일을 실행시킵니다.
rake "crawl:example"
6. 결과를 확인해보세요!
크롤링이 잘 된게 확인될겁니다.
- Chapter 3 로그인 후, javascript 렌더링 홈페이지 크롤링 하기
참고 해당 실습 으로서는 대학 커뮤니티 중 하나인 에브리타임 글을 가져오는 것을 예시로 하겠습니다.
실습 전 유의사항
1. Step 1 과정이 완료되어 있어야 합니다.
2. 이번 설명에는 API 키가 쓰여집니다. 외부에 노출되면 과금의 우려가 있을 수 있으니, Figaro Gem 설치를 통해 설명하겠습니다.
3. Figaro Gem에 대한 자세한 설명은 생략합니다.
참고 Figaro Gem
1. 계정 로그인을 통해 크롤링을 사용하는 방식이다 보니, 향후 정보 보호를 위해 Figaro Gem을 설치합니다.
gem 'figaro'
2. config/application.yml 파일을 생성 후, 다음 내용을 입력합니다.
## config/application.yml
EVERYTIME_ID: "..."
EVERYTIME_PW: "..."
3. 새로운 task 파일을 생성합니다.
rails g task everytime example
4. lib/tasks/everytime.rb 파일에 다음 내용을 복사/붙여넣기 합니다.
namespace :everytime do
desc "TODO"
task example: :environment do
Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
## 헤드리스 개념 : https://beomi.github.io/2017/09/28/HowToMakeWebCrawler-Headless-Chrome/
options = Selenium::WebDriver::Chrome::Options.new # 크롬 헤드리스 모드 위해 옵션 설정
options.add_argument('--disable-extensions')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
# 셀레니움 + 크롬 + 헤드리스 옵션으로 브라우저 실행
@browser = Selenium::WebDriver.for :chrome, options: options
# 로그인 페이지 가기
browser = @browser.get 'https://everytime.kr/login'
# 여러 Form중에 id="id"인 Form을 가리킨 후, 아이디 입력
inputID = @browser.find_element(name: "userid").send_keys "#{ENV['EVERYTIME_ID']}"
# 여러 Form중에 id="id"인 Form을 가리킨 후, 비밀번호 입력
inputPW = @browser.find_element(name: "password").send_keys "#{ENV['EVERYTIME_PW']}"
# '로그인' 버튼 클릭
@browser.find_element(css: "p.submit > input.text").click
# 다음 페이지로 이동
@browser.navigate().to "https://everytime.kr/380617"
## find_element랑 find_elements의 차이를 꼭 알아두자.
# https://stackoverflow.com/a/14425080
## 에브리타임 게시글은 javascript로 데이터를 받아온 후, 사용자에게 보여주다보니, 1초의 Term을 줘야합니다.
## 1초의 Term을 안주면 데이터 조회 결과가 안나옵니다.
sleep(1)
@content = @browser.find_elements(xpath: '//*[@id="container"]/div[2]/article')
@content.each do |t|
@title = t.find_element(css: "h2.medium").text
@nickname = t.find_element(css: "h3.small").text
@date = t.find_element(css: "time.small").text
@url = t.find_element(tag_name: "a").attribute("href")
## 서버 로그 확인용
# puts "제목 : #{@title} / 닉네임 : #{@nickname} / 작성기간 : #{@date} / URL : #{@url}"
Market.create(title: @title, nickname: @nickname, date: @date, url: @url)
end
@browser.quit
end
end< 코드 리뷰 >
1) 홈페이지 로그인을 돕는 코드
browser = @browser.get 'https://everytime.kr/login'
inputID = @browser.find_element(name: "userid").send_keys "#{ENV['EVERYTIME_ID']}"
inputPW = @browser.find_element(name: "password").send_keys "#{ENV['EVERYTIME_PW']}"
@browser.find_element(css: "p.submit > input.text").click
2) 에브리타임은 자료를 불러올 때 아래 사진과 같이 javascript를 통해 데이터를 받아온 후, 사용자에게 보여주다보니,
크롤링 전에 1초의 텀을 줘야합니다.
sleep(1)
3) 게시글 목록 한 줄을 나타내는 Xpath
@content = @browser.find_elements(xpath: '//*[@id="container"]/div[2]/article')이번 실습 때에는 xpath를 활용하여 크롤링 대상을 가리켰습니다.
xpath는 크롬 브라우저에서 F12 를 누르면 나오는 개발자 도구를 통해 알 수 있습니다.
다만, 위 정석대로 xpath를 추출하면
//*[@id="container"]/div[2]/article[1]다음과 같은 결과가 나오게 됩니다만,
해당 경로는 첫 번째 게시글만 가리키므로, 저희는 모든 게시글에 대한 정보를 알아야 하기에 article[1]에서 [1]을 제거했습니다.
4) find_elements / find_element
- find_elements : 크롤링으로 가져온 데이터 중, 하나만 가지고 있습니다.
- find_element : 여러 개의 데이터 정보를 가지고 있으며, 하나로 뭉쳐친 데이터에 대해 각각의 결과는 each do 문법을 통해 확인합니다.
4. app/controller/homes_controller.rb 로 이동 후, 다음 내용을 입력합니다.
class HomesController < ApplicationController
def index
@data_list = Market.all
end
end
5. app/model/market.rb 파일을 열람 후, 데이터의 중복저장을 막기위해 다음 내용을 작성합니다.
class Market < ApplicationRecord
validates_uniqueness_of :title
end
6. app/views/homes/index.html.erb 에 다음 내용을 입력합니다.
<% @data_list.each do |t| %>
<div><%= t.title %> | 작성자 : <%= t.nickname %> | 등록 : <%= t.date %> <%= link_to "[이동]", t.url, target: "_blank" %></div>
<hr/>
<% end %>
7. 다음 명령어를 통해 lib/tasks/crawl.rb 파일을 실행시킵니다.
rake "crawl:example"
8. 결과를 확인해보세요!
크롤링이 잘 된게 확인될겁니다.
- 이슈 Selenium::WebDriver::Error::WebDriverError (unable to connect to chromedriver 127.0.0.1:9515) 에러 발생시
다음 Gem을 재 설치 후, 다시 시도해보세요.
1) chromedriver-helper Gem을 지웁니다.
gem uninstall chromedriver-helper
2) 다시 Gem을 설치합니다.
bundle install
- 이슈 Selenium::WebDriver::Error::WebDriverError: not executable
위와같은 에러를 겪은 경우, chromedriver-helper Gem의 버전을 특정지어서 설치를 하면 됩니다.
# gem 'chromedriver-helper'
=> gem 'chromedriver-helper', '1.2.0'
- 이슈 WebDriverError: not a file: "" 에러 발생
이 문제는chromedriver-helper의 버전을 1.2.0 으로 맞췄기 때문입니다.
gem 'chromedriver-helper', '1.2.0'
Selenium 코드 중에
Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp위 코드가 있는 부분이 있는데, 원래 여기서
which chromedriver-helper명령어를 터미널에 입력 시
which chromedriver-helper
=> /home/ubuntu/.rvm/gems/ruby-2.6.3/bin/chromedriver-helper위와같이 Response Return이 와야 하는데, 지금 시도를 해보면 반응이 없는 문제점이 발생합니다.
그래서 이 문제를 해결할 수 있는 방법은
Selenium::WebDriver::Chrome.driver_path = `which chromedriver`.chompwhich chromedriver-helper 를 which chromedriver 로 바꿔주면 작동이 잘 될겁니다.
- 이슈 Heroku에서 Push가 안되어서 문제가 생깁니다.
Gemfile 파일을 열람 후 보면, Development Group 안에 있는 상태입니다.
## Gemfile
group :test do
...
gem 'selenium-webdriver'
end반면 Heroku는 배포환경이 Production 이다 보니, 정작 Heroku 배포 땐 인식을 못하는 문제가 발생하게됩니다.
Development Group 안에 있는 gem 'selenium-webdriver' 을 그냥 Group 밖으로 빼내주시면 됩니다.
(Production 환경이 인식만 할 수 있게 하면 됩니다.)
추가적으로, 혹시 모르니
헤로쿠와 연결된 상태에서 터미널을 통해 다음 Add-On을 설치해주세요.
heroku buildpacks:add --index 1 https://github.com/heroku/heroku-buildpack-chromedriver
heroku buildpacks:add --index 2 https://github.com/heroku/heroku-buildpack-google-chrome주의 헤로쿠 Repository에 있어, 프로젝트가 이미 Push가 되어있는 상태에서 위 명령어 입력해주세요.
프로젝트 파일이 Push 전 위 명령어를 입력하면 프로젝트의 언어를 인식 못하는 문제가 발생됩니다.
그리고 bundle install 후, 다시 Heroku로 Push 해보세요.
bundle install
git push heroku master주의 Push가 안될경우 그냥 아주 조그맣게라도 Push거리를 만들어내고, Push를 해주세요.
- 이슈 윈도우에서 chrome-driver 에러 발생
해당 문제는 해결방법이
Chrome-driver Gem 파일을 구성하는 파일 중 하나인 platform.rb 파일을 건들여야 합니다.
1. 다음 명령어를 통해 platform.rb 파일을 찾아냅니다.
1) 초록네모로 표시된 부분을 마우스로 클릭해서 platform.rb 파일을 열람할 수 있거나,
2) 다음 명령어를 통해서 찾아볼 수도 있습니다.
find / -name "platform.rb"
2. 해당 파일을 열람합니다.
3. 코드를 수정합니다.
1) 아래의 코드를
def assert_executable(path)
assert_file(path)
return if File.executable? path
raise Error::WebDriverError, "not executable: #{path.inspect}"
end
2) 다음과 같이 수정해주면 됩니다.
def assert_executable(path)
assert_file(path)
return nil
raise Error::WebDriverError, "not executable: #{path.inspect}"
end
- 이슈 Heroku / Ubuntu 크롬 브라우저 버전이 맞지않아서 Selenium 미작동
해당 사례는 처음에 Heroku에서 겪었던 사례입니다.
헤로쿠에서 어느 날 갑자기 Selenium에 에러가 생겼길레, 로그기록을 통해서 확인을 해보는데 위와같은 기록이 발견되었습니다.
그런데 여기서 눈에 띄는 것은 빨간 네모로 표시된 문구입니다.
혹시나 해서 제 크롬 브라우저 버전을 확인해 본 결과..
heroku run google-chrome --version
76 버전이었네요..
해당 이슈 해결법은 간단하게도 google-chrome 빌드팩을 삭제했다 다시 설치하면 됩니다.
Heroku 해결 방법
1. http://herokuapp.com 페이지로 가셔서 헤로쿠 로그인을 합니다.
2. 로그인 후, 크롬 버전을 업데이트 하고자 하는 프로젝트로 가신 후, Setting 페이지로 이동합니다.
3. Setting 페이지에서 조금만 아래로 내려가면 Buildpacks 설정란이 보입니다.
여기서 google-chrome 빌드팩을 삭제합니다.
4. 터미널로 돌아가서, 명령어를 통해 빌드팩을 재설치 합니다.
heroku buildpacks:add --index 2 https://github.com/heroku/heroku-buildpack-google-chrome
5. Github를 통해 Heroku에 자료 최신화를 합니다.
git add .
git commit -m "Heroku chrome 수정"
git push heroku master주의 Push가 안될경우 그냥 아주 조그맣게라도 Push거리를 만들어내고, Push를 해주세요.
6. 다시한번 Chrome 버전을 확인해보세요.
최신화 되어있는게 확인될 겁니다.
heroku run google-chrome --version
Ubuntu 해결방법
1. 이전 chrome-driver을 지웁니다.
sudo apt-get -y purge chromium-chromedriver
2. 다시 최신 버전으로 설치합니다.
sudo apt-get update
sudo apt-get -y install chromium-chromedriver
위 명령어를 다시 입력해봐도 최신 버전이 안깔리는 경우 다음 과정을 진행합니다.
3. rake 파일로 열람 후, 다음 코드를 코드 맨 앞에 # 기호를 붙여줘서 주석처리를 해줍니다.
Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
=> # Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
4. 만약 배포(Production) 모드에 있어, Heroku를 쓰시는 경우 3번 과정의 코드를 주석처리 시 에러가 발생합니다.
다음과 같이 코드를 변경해주세요.
if Rails.env.development?
# Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
else
Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
end
- 주의 Gem 사용 유의사항
@browser.quit크롤링을 마치면 반드시 브라우저 종료(quit) 처리를 해주세요.
해당 처리를 안해주면 메모리가 계속 쌓이게 되고, 메모리 스택 오버플로우(메모리 초과)가 발생될 수 있습니다.
- Selenium의 비효율적인 퍼포먼스
부록 캐치딜 백엔드 개발이야기 : 크롤링
Selenium은 다 좋은데, 한가지 문제점이 있습니다.
바로 메모리 사용량이 너무 크다는 겁니다.
Selenium 사용에 있어 메모리 사용이 얼마나 심한지 한번 다음 예시를 통해 살펴보겠습니다.
예를들어 위 뉴스 페이지 내용 중, 빨간 영역의 기사 타이틀 및 내용을 크롤링을 해본다고 해보겠습니다.
1) Nokogiri
## CrawlNokogiriJob.perform_now(:running_nokogiri)
class CrawlNokogiriJob < ApplicationJob
def running_nokogiri
doc = Nokogiri::HTML(open("https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=102"))
@crawl_data = doc.css('#main_content > div.list_body.newsflash_body > ul.type06_headline > li > dl')
@crawl_data.each do |t|
@title = t.css('dt:nth-child(2) > a').text.strip
@content = t.css('dd > span.lede').text.strip
puts "#{@title} || #{@content}"
end
end
end
2) Selenium
## CrawlSeleniumJob.perform_now(:running_selenium)
class CrawlSeleniumJob < ApplicationJob
def running_selenium
if Jets.env == "production"
Selenium::WebDriver::Chrome.driver_path = "/opt/bin/chrome/chromedriver"
options = Selenium::WebDriver::Chrome::Options.new(binary:"/opt/bin/chrome/headless-chromium")
else
Selenium::WebDriver::Chrome.driver_path = `which chromedriver-helper`.chomp
options = Selenium::WebDriver::Chrome::Options.new
end
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
@browser = Selenium::WebDriver.for :chrome, options: options
@browser.navigate().to "https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=102"
@crawl_data = @browser.find_elements(css: "#main_content > div.list_body.newsflash_body > ul.type06_headline > li > dl")
@crawl_data.each do |t|
begin
@title = t.find_element(css: "dt:nth-child(2) > a").text.strip
@content = t.find_element(css: "dd > span.lede").text.strip
puts "#{@title} || #{@content}"
rescue
end
end
@browser.quit
end
end
AWS Lambda에서 동일한 페이지 내 영역에 대해 크롤링을 돌려보겠습니다.
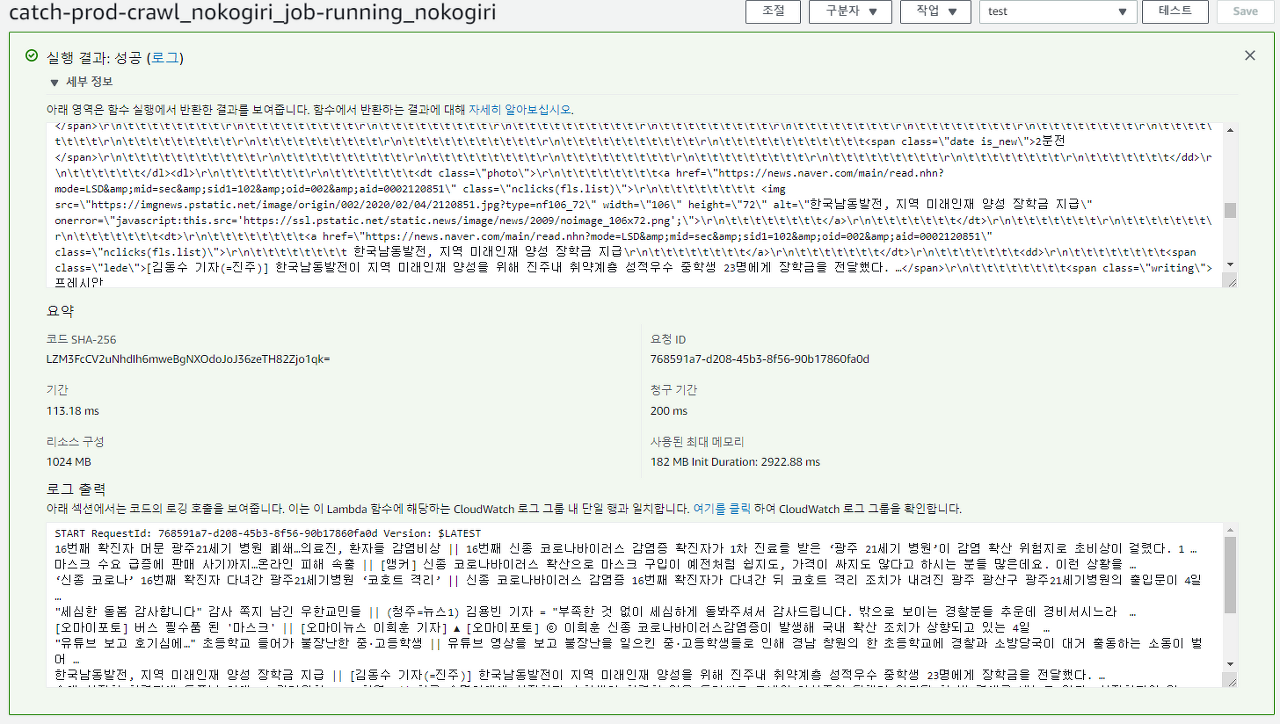
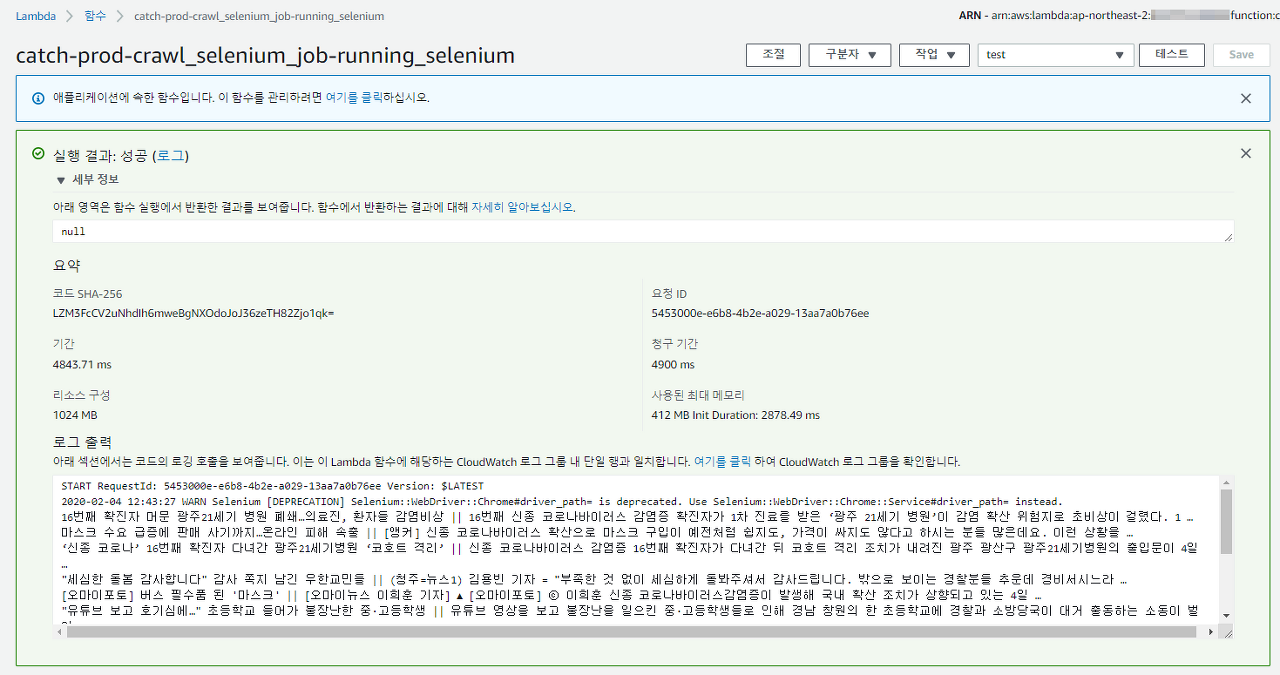
각기 다른 크롤링을 돌려보면 다음과 같은 결과를 살펴볼 수 있습니다.
| 크롤링 비교 | 소요시간 | 사용 메모리 |
| Nokogiri | 200ms (0.2 Second) | 182MB |
| Selenium | 4900ms (4.9 Second) | 412MB |
이와같이 Selenium은 크롤링에 있어 퍼포먼스 적으로는 떨어진다는 것이 확인이 됩니다..ㅠ
- 이슈 Chrome not reachable, Selenium 임시파일
참고 해당 이슈는 스토리 형식으로 풀어나가겠습니다. 결론만 궁금하신분은 색깔이 씌어진 글씨만 읽어주세요.
제가 운영하는 서비스 중, 5분에 한번씩 서버에서 정기적으로 Selenium 크롤러가 돌아가는 작업이 있습니다.
그런데 어느 날 갑자기 크롤링을 시도하려 하면 chrome not reachable 에러메세지를 겪게 되었습니다. 하지만 이상한게, 테스트서버 내부에서 또한 똑같은 크롤링 코드를 돌리면 작동이 잘 됐습니다.
일단 코드쪽 문제는 아닌 것 같아서 혹시나 하고
## 서버 용량을 확인하는 명령어 (MB 단위로 확인)
df -m위 명령어를 통해 서버 내 용량(Volume)을 한번 살펴봤습니다.
원인은 역시 서버 용량이었습니다.
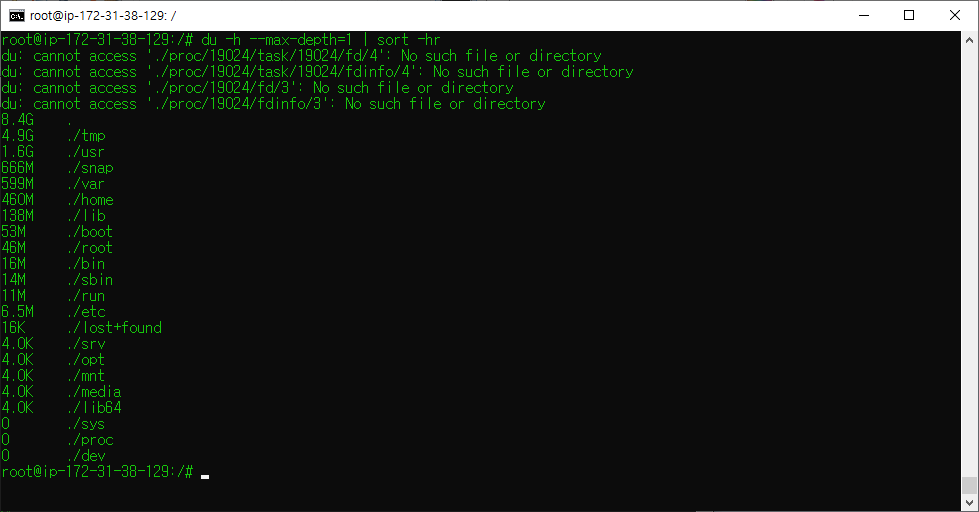
일단 서버용량이 원인인건 알아냈는데, 어느 파일에서 용량이 이렇게 많이 새어나오는질 몰라서
## 현재위치 기준 바로 아랫단계 폴더까지만 탐색 및 용량 체크 및 용량 순으로 정렬
sudo du -h --max-depth=1 | sort -hr위에 적어놓은 명령어를 통해 여러 디렉토리를 다 뒤져가며 디렉터리/파일 용량을 체크하며 알아봤습니다.
그 결과, 최종적으로 원인은 최종적으로 /tmp 폴더 내에 있는 chromium 및 google 임시파일들이 쌓여져 갔던게 원인임을 확인했습니다.
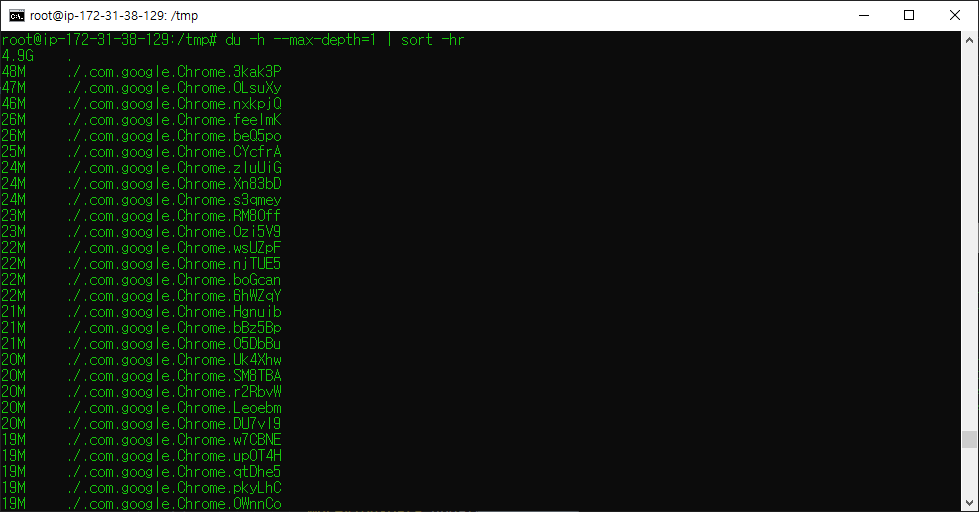
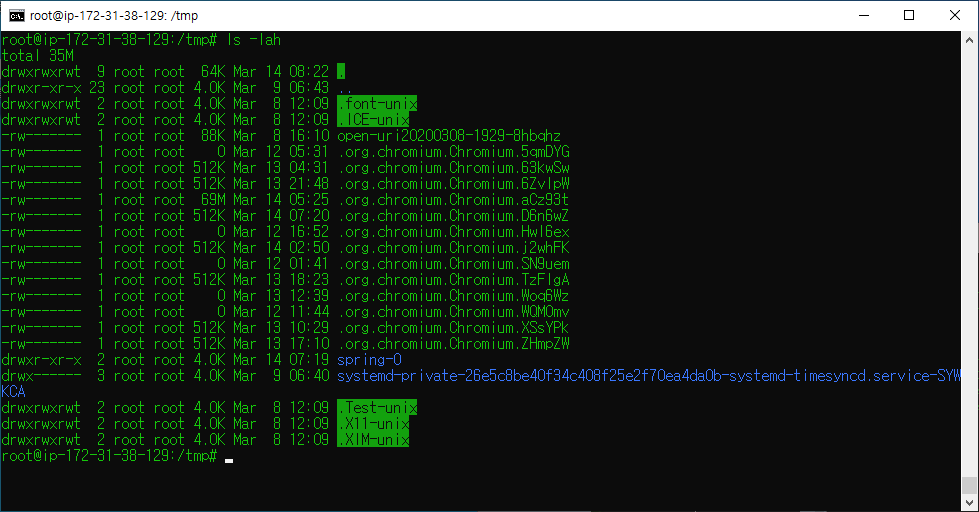
그리하여 저는 최종적으로 rm 명령어를 통해 임시파일들을 다 지웠습니다.
rm -rf .com.google.Chrome
rm -rf .org.chromium.Chromium.*임시파일들을 다 지운 후, 다시 용량을 확인해보니 이제 서버의 용량이 넉넉하게 확보됐음을 확인했습니다.
참고 Selenium 이랑 chrome이랑 무슨 연관이 있냐고 묻는다면, 초반에 말했다 싶이 Selenium은 가상 브라우저(chrome 등) 기반으로 동작하는 크롤러 입니다.
- 자료 참고
1. 원노 님 [클릭]
2. Heroku로 Push가 안되는 문제 [클릭]
3. Linux 기반 크롬 설치 [클릭]
4. Selenium::WebDriver::Error::WebDriverError: not executable 에러 해결법 [클릭]
'프로그래밍 공부 > Ruby on Rails : Gem' 카테고리의 다른 글
| Ruby on Rails : 세션이 유지된 로그인 [Gem : Mechanize] (0) | 2019.12.16 |
|---|---|
| Ruby on Rails : JWT with devise [gem : jwt] (0) | 2019.12.06 |
| Ruby on Rails : Nokogiri 크롤링 [Gem : nokogiri] (0) | 2019.12.05 |
| Ruby on Rails : DB 백업하기 (PostgresDB 기준 설명) [Gem : backup, whenever] (0) | 2019.12.05 |
| Ruby on Rails : 선입선출 Background Job [Gem : sidekiq] (0) | 2019.12.03 |
