
티스토리 뷰
Ruby on Rails : 선입선출 Background Job [Gem : sidekiq]
나른한 하루 2019. 12. 3. 13:46해당 글은 https://blog.naver.com/kbs4674/221658347447 로 부터 게시글이 이전되었습니다.
일반적으로 레일즈는 서버를 작동을 시키면 터미널에서 아무것도 입력을 못하는 상태가 됩니다.
하지만 Background Job은 서버가 돌아가는 작업이 이루어지는 동시에, 무언가의 작업이 이루어지는것을 뜻합니다.
(작업이라 하면은 이메일 전송 등이 되겠죠!)
이번 시간은 Background Job 및 이를 쉽게 사용하도록 도와주는 sidekiq Gem에 대해 알아보도록 하겠습니다.
- 개념 Background Job을 순차적으로
Background Job에 있어서도,
-
작업이 들어오자 마자 바로 진행할건지
-
여러개의 작업이 들어오긴 했으나, 들어온 순서대로 순차적으로 진행할건지
위와같은 방식을 생각해볼 수 있습니다.

소량의 데이터를 처리한다면 위의 2가지 방법에 대해선 티가 거의 잘 안나겠으나, 만약에 대량의 작업이 한번에 유입이 된다면 한번 생각을 해봐야 될 수 있는 이슈입니다.
※ 예시 : 수강신청 때 하나의 과목에 대해 동시적으로 클릭을 한다면? / 대량의 이메일/문자를 전송해야 할 때
선입선출 Background Job을 도입을 하지 않는다는 것은 일상 생활로 비유해 본다면,
손님이 은행에 갔을 때 대기표를 뽑지 않고, 바로 창구에 가는 꼴 입니다.
창구가 한산하다면 상관없겠지만, 수많은 사람들이 몰린다면 업무에 지장(stuck)이 생길겁니다.
현재의 은행 시스템은 손님이 바로 은행 창구에 가지 않고 기계에서 대기표를 받은 후, 은행 창구가 꽉 찬 경우 잠시 앉아서 대기했다가 호명되는 번호 순서대로 은행업무를 보는 형태입니다.
이번에 소개드릴 시스템이 바로 현재의 은행시스템과 같은 원리라고 보시면 되겠습니다.

컴퓨터학과 전공을 하신 분들은 아시겠지만, 이렇게 순차적으로 진행하는 방식을 선입선출(큐) 방식이라고 합니다.
이번에 소개 될 글 또한 선입선출 방식으로, 순차적으로 Background 작업이 이루어 지는 방식에 대해 소개시키고자 합니다.
이를 위해 사용될 Gem은 사이드 킥(sidekiq)이 되겠습니다.
참고로, Background 작업이 이루어 지긴 하나, 순차적인 방식이 아닌 '시간을 따로 정해서 작업을 하는 방식'에 대해서도 방법이 존재합니다.
해당 방법에 대해서는 whenever Gem 부분을 참고해주시면 되겠습니다.
부록 Whenever Gem을 통한 스케쥴링 Background 작업 [클릭]
-
Chapter 1 Redis-server 설치
참고 AWS EC2의 Ubuntu 환경을 기준으로 설치방법 설명이 진행됩니다.
선입선출 방식의 Background를 하기전에 앞서, 이를 도와주는 Sidekiq Gem은 Redis-server에 의존되는 방식입니다.
그렇다보니 Redis-server을 설치를 해줘야 합니다.
1. 외부 서버로부터 redis 설치 파일을 받아온 후, Redis를 설치합니다.
cd /tmp
wget http://download.redis.io/releases/redis-4.0.0.tar.gz
tar xzf redis-4.0.0.tar.gz
rm -rf redis-4.0.0.tar.gz
cd redis-4.0.0
make
2. 서버 내 Redis 공간을 마련해줍니다.
그리고 실행파일(redis-server)과 Redis 설정파일(redis.conf)를 Copy/Paste 합니다.
sudo mkdir /etc/redis
sudo mkdir /var/lib/redis
sudo cp src/redis-server src/redis-cli /usr/local/bin/
sudo cp redis.conf /etc/redis/
3. AWS EC2에서 Redis-server 이 돌아가게 하도록 EC2에 맞춘 redis-server 패키지 설치를 진행합니다.
cd /tmp
wget https://raw.github.com/saxenap/install-redis-amazon-linux-centos/master/redis-server
4. redis-server을 실행합니다.
redis-server /etc/redis/redis.conf
참고1 redis-server 종료는 키보드에서 Ctrl+C 키를 눌러주면 됩니다.
참고2 /etc/redis/redis.conf 는 redis 설정을 하는 파일입니다.
redis 파일을 설정할 일(redis 암호설정 등)이 있으면 /etc/redis/redis.conf 파일에서 하면 됩니다.
-
Chapter 2 Sidekiq Gem 설치 및 초기 설정
Sidekiq Gem 설치 및 sidekiq, Redis 설정에 대해 다뤄보겠습니다.
1. Gemfile 로 이동 후, sidekiq 및 redis-server 관련 Gem을 설치합니다.
## Gemfile
# sidekiq
gem 'sidekiq'
gem 'connection_pool'
gem 'redis-namespace'
# 환경변수
gem 'figaro'
2. config/application.rb 로 이동 후, Background Job에 쓰일 수단에 대해 정의합니다.
config.active_job.queue_adapter = :sidekiq## config/application.rb
... (내용 생략) ...
module Kcm
class Application < Rails::Application
# Initialize configuration defaults for originally generated Rails version.
+ config.active_job.queue_adapter = :sidekiq
config.load_defaults 5.2
# config.active_job.queue_name_prefix = Rails.env
# Settings in config/environments/* take precedence over those specified here.
# Application configuration can go into files in config/initializers
# -- all .rb files in that directory are automatically loaded after loading
# the framework and any gems in your application.
end
end
3. config/application.rb 상단에 모듈(require) 을 정의합니다.
require 'sidekiq/web'## config/application.rb
... (내용 생략) ...
+ require 'sidekiq/web'
module Kcm
class Application < Rails::Application
+ config.active_job.queue_adapter = :sidekiq
... (내용 생략) ...
end
end
3. config 위치에서 sidekiq.yml 파일을 새로 생성 후, 다음 내용을 작성해서 각각 기능에 대해 초기 설정을 합니다.
## config/sidekiq.yml
# 사실 logfile 이 의미가 있긴 할지 모르겠지만.. 일단 적어두겠습니다.
# (실제로 logfile 위치를 가리키는것은 config/initializers/sidekiq.rb 에 입력했던 log_file_path 변수 입니다.)
:pidfile: ./tmp/pids/sidekiq.pid
:daemon: true
development:
:verbose: true
:logfile: ./log/development_sidekiq.log
:concurrency: 7
:timeout: 30
:queues:
- modified_post
- mailers
production:
:verbose: false
:logfile: ./log/production_sidekiq.log
:concurrency: 7
:timeout: 5
:queues:
- modified_post
- mailers주의 :queues 에서 queue 명칭을 잘 적어놔주세요. 차 후에 생성될 Job에 대해서 Queue 명칭을 정하는데, Job에서 설정된 Queue 이름이랑 sidekiq.yml에 명시되어있는 queue랑 명칭이 다르면 Background 작업이 안됩니다.
참고1 concurrency는 sidekiq 내에서 프로세스가 실행되는 작업 갯수를 의미합니다.
4. concurrency 유의사항 sidekiq 공식문서에 의하면, Rails 5 기준에서는 concurrency의 수치를 50을 넘지 않는것을 추천한다고 합니다.
또한 sidekiq은 작업을 수행하는 Thread를 기본으로 10개를 생성을 하니, 이에 따라 config/database.yml 에서도 Threadpool을 최소 10개 이상으로 조절합니다.
## config/database.yml
production:
adapter: <%= ENV['DATABASE_ADAPTER'] || "sqlite3" %>
database: foo_production
+ pool: <%= ENV['RAILS_MAX_THREADS'] || 10 %>
5. config/initializers 위치로 이동 후, sidekiq.rb 및 redis.rb 파일을 새로 생성 후 코드를 입력해주세요.
1) config/initializers/sidekiq.rb
sidekiq을 여러개 생성 시, redis 작업에 있어 충돌을 방지 및 쓰레드 관리를 합니다.
## config/initializers/sidekiq.rb
# LOG파일 위치 지정
log_file_path = "#{Rails.root}/log/#{Rails.env}_sidekiq.log"
Sidekiq.configure_server do |config|
config.redis = REDIS_POOL
config.logger = Logger.new(log_file_path)
end
Sidekiq.configure_client do |config|
config.redis = REDIS_POOL
end
# [Option] Exception 사유로 Job이 종료가 될 시, 다시 Job 시도 및 횟수를 정하는 코드입니다.
Sidekiq.default_worker_options = {retry: 1}참고1-1 server랑 client랑 따로 생성하는 이유 [클릭]
2) config/initializers/redis.rb
## config/initializers/redis.rb
# Sidekiq threadpool 생성
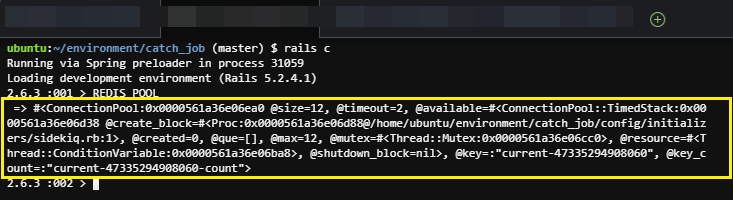
REDIS_POOL = ConnectionPool.new(:size => 7 + 5, :timeout => 2) { Redis::Namespace.new("sidekiq_job", redis: Redis.new(:url => "redis://#{ENV['REDIS_HOST']}:6379")) }참고2-1 Connectpool 사이즈는 Connectpool = concurrency + 5 (혹은 Connectpool = concurrency + 2) 가 좋다고 명시되어 있습니다. [참고1] [참고2]
참고2-2 나중에 REDIS_POOL 변수를 Console을 통해 조회해 보면 다음과 같이 결과가 보여지는 것을 확인할 수 있습니다.
6. config 폴더에 application.yml 파일을 생성 후, 5번 과정 때 작성했던 환경변수에 대한 Value를 입력합니다.
## config/application.yml
# Redis 호스트
REDIS_HOST: localhost
7. config/routes.rb 에서 다음 내용을 추가해주세요.
mount Sidekiq::Web => '/sidekiq'적용 예시 :
## routes.rb
Rails.application.routes.draw do
... (내용 생략) ...
+ mount Sidekiq::Web => '/sidekiq'
end
8. 터미널에 다음 명령어를 입력해서 redis-server을 켜주세요. (이미 켜져있을 경우 껏다 켜주세요.)
참고 screen[클릭] 을 활용해서 redis server을 킬 것을 추천드립니다.
redis-server /etc/redis/redis.conf
9. 터미널에 다음 명령어를 입력해서 sidekiq 프로세스 및 콘솔을 킵니다.
참고 screen[클릭] 을 활용해서 sidekiq을 킬 것을 추천드립니다.
sidekiq
참고 1 sidekiq 종료는 키보드에서 Ctrl+C 키를 눌러주면 됩니다.
참고 2 Production 에서 사용 시에는 아래 명령어를 입력해줘야 합니다.
## Production Environment
RAILS_ENV=production rails c참고 3 지금은 로그파일에 sidekiq 로그기록이 쓰여지는 방식이다 보니 콘솔창에는 로그기록이 안보이지만, 원래는 Sidekiq 실행 시 다음과 같이 표시됩니다.

10. http://(홈페이지 주소)/sidekiq 으로 이동하면 sidekiq 대시보드 페이지를 보실 수 있습니다.

참고 1 메인 페이지는 Poilling Interval 타임 동안 계속 상황이 refresh 됩니다.
참고 2 sidekiq 페이지에 이동 후, 레일즈 콘솔창을 보면 Poilling Interval 타임 단위로 항상 Listining 상태인 것을 보실 수 있습니다.
-
Chapter 3 Active Job 생성
Active Job 은 레일즈에서 어떤 작업에 대해 Background Job이 이루어지도록 도와주는 기능입니다.
저희는 해당 기능을 이용해서 Background 연동을 해볼겁니다.
1. 터미널에 다음 명령어를 통해 Active Job을 생성해줍니다.
rails g job post_update
2. app/jobs 위치에 post_update_job.rb 파일이 새로 생성된게 확인됩니다.
## app/jobs/post_update_job.rb
class PostUpdateJob < ApplicationJob
queue_as :default
def perform(*args)
# Do something later
end
end
1) queue_as :default Queue 이름을 설정합니다.
해당 Queue 이름은 과거에 언급했다 싶이 Chapter 2 에서 confog/sidekiq.yml 파일의 :queues 목록에 Queue 이름이 명시되어 있어야 작동이 됩니다.
2) def perform(*args) ... end Background 작업에서 실행 될 작업에 대해 해당 메소드 안에 표현을 해내시면 됩니다.
참고로 해당 메소드가 메인 메소드라고 보시면 됩니다. (C언어로 치면 메인함수)
3) (*args) 외부로 부터 변수를 받아냅니다.
-
Sidekiq + Background Job 응용사례 1 주기적인 게시글 수정
간단하게 Sidekiq + Background 작업을 통해 작성된 게시글에 대해 일정시간 간격으로, 무조건 제목이 "안녕하세요" 로 수정되게 작업을 수행해보겠습니다.
1. app/jobs/post_update_job.rb 파일을 다음과 같이 수정합니다.
## app/jobs/post_update_job.rb
class PostUpdateJob < ApplicationJob
queue_as :modified_post
def perform(post_meterial)
post_meterial.update(title: "안녕하세요")
end
end
2. config/sidekiq.yml 파일에서 queues에서 Queue 이름을 명시해주세요.
* 1번 과정에 있어 Active Job이 modified_post 라는 이름의 Queue를 활용하는 만큼, sidekiq.yml 파일에 다음과같이 적용을 해야합니다.
## config/sidekiq.yml
:pidfile: ./tmp/pids/sidekiq.pid
:daemon: true
development:
:verbose: true
:logfile: ./log/sidekiq.development.log
:concurrency: 5
:timeout: 30
:queues:
- modified_post
- mailers
production:
:verbose: false
:logfile: ./log/sidekiq.production.log
:concurrency: 10
:timeout: 5
:queues:
- modified_post
- mailers
3. 간단한 실습을 위해 Post Scaffold를 생성합니다.
rails g scaffold posts title그리고 DB 스키마를 최신화를 합니다.
rake db:migrate
4. Post Controller에 다음 내용을 추가해주세요.
PostUpdateJob.perform_later(@post)위 코드는 실행되면, app/jobs/post_update_job.rb 파일이 실행이 되게 하는 트리거 역할을 합니다.
아래 코드와 같이 Post가 Save 시, 발동이 되도록 하면 됩니다.
## app/controllers/posts_controller.rb
class PostsController < ApplicationController
... (내용 생략) ...
def create
@post = Post.new(post_params)
respond_to do |format|
if @post.save
format.html { redirect_to @post, notice: 'Post was successfully created.' }
format.json { render :show, status: :created, location: @post }
PostUpdateJob.perform_later(@post)
else
format.html { render :new }
format.json { render json: @post.errors, status: :unprocessable_entity }
end
end
... (내용 생략) ...
end
5. Rails 서버를 껏다 켜주세요.
6. 터미널에 다음 명령어를 입력해서 sidekiq 프로세스 및 콘솔을 킵니다.
sidekiq 콘솔을 통해 sidekiq 실행 및 Background Job 과정을 로그로 살펴볼 수 있습니다.
## Development Environment
sidekiq참고 1 sidekiq 종료는 키보드에서 Ctrl+C 키를 눌러주면 됩니다.
7. 직접 Post Scaffold에 내용을 입력해서 결과를 확인합니다.
Step 1 제목을 "나는 빡빡이다" 라고 글을 작성

Step 2 Sidekiq 콘솔창에서 뭔가 작업이 이루어졌다고 로그기록이 찍힘.

Step 3 바로 Scaffold 목록을 확인하면 내용이 바껴져 있는게 확인

-
Sidekiq + Background Job 응용사례 2 이메일 전송
참고 이메일 전송 관련 인프라 과정은 본 설명에서는 생략합니다.
부록 Email 전송 https://blog.naver.com/kbs4674/221386948816
과거 제가 이메일 전송 관련 글을 다뤘을 때에는, 처리가 즉각 이루어 지는 방식으로 이루어 졌다보니, Active Job으로 이루어지는 형식과는 거리가 멀었었습니다.
SendmailMailer.email_send(@post).deliver_now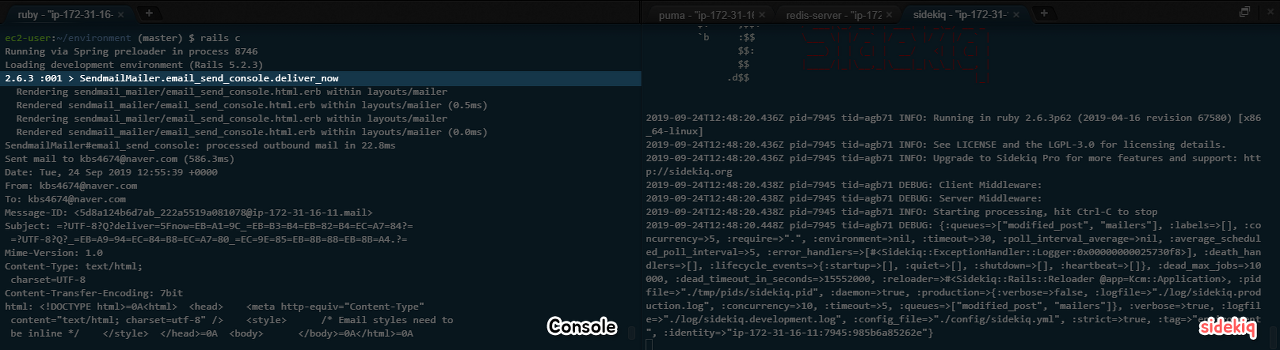
과거에 메일을 보낼 때 당시 활용된 메소드인 deliver_now는 순전히 바로 일처리를 진행하는 방식이었습니다.
그런데 deliver_now 외에도 사실 Background 작업을 지원하는 deliver_later 라는 메소드도 존재했었습니다.
이제 deliver_later 메소드를 이용해서 메일을 보내보면

Background Job + 순차적인 방식(큐)으로 메일을 보내지는게 확인이 됩니다.
참고 이메일 전송 관련 Queue 이름은 mailers 입니다.
결국 위 사례를 봤을 때, deliver_now은 Background Job 방식은 아니고, deliver_later 메소드를 써야지 Background Job으로 작동된다는 걸 알 수 있습니다.
이에 대한 설명은 다음 목차에 자세히 설명해보겠습니다.
-
메소드 개념 설명 perform_now VS perform_later
시작 전 위 메소드 들의 명확한 차이를 콘솔창에서 눈으로 확인해보고자 잠시 아래와 같이 코드를 주석처리를 해주세요.
config/initializers/sidekiq.rb
# config.logger = Logger.new(log_file_path)## config/initializers/sidekiq.rb
... (내용 생략) ...
log_file_path = "#{Rails.root}/log/#{Rails.env}_sidekiq.log"
Sidekiq.configure_server do |config|
config.redis = REDIS_POOL
# config.logger = Logger.new(log_file_path)
end
... (내용 생략) ...Job 방식에 있어, 크게 perform_now 와 perform_later 로 나뉩니다.
그동안 perform_later에 대해서만 언급하고, perform_now에 대해서는 설명을 안했었는데 이 두 부분에 대한 차이를 설명해보고자 합니다.
1) perform_now
Perform_now 은 들어오는 작업에 대해 Background 작업 및 대기 없이 바로 처리를 시켜버리는 메소드 입니다.

2) perform_later
Perform_later 은 들어오는 작업에 대해 Background 작업 및 Queue에 대기 후 순차적으로 작업을 처리하는 방식입니다.

-
perform과 함께 쓰는 메소드, Queue 이름을 유동적으로(Prefix)
1) perform과 함께 쓰는 메소드
perform 메소드 사용에 있어 시간지연을 시켜주는 메소드가 존재합니다.
바로 Set 이라는 메소드인데요, Set 명령어를 통해서 메소드 사용을 지연을 시킬 수 있습니다.
해당 메소드는 perform_now, perform_later, deliver_later 메소드에 사용이 가능합니다.
SendmailMailer.email_send.deliver_later(wait: 0.1.minute)
=> 0.1분(10초) 후 작업 시행(해당 코드 예시에서는 메일 발송)
SendmailMailer.email_send.deliver_later(wait: 1.minute)
=> 1분 후 작업 시행(해당 코드 예시에서는 메일 발송)
AnyJob.set(wait: 0.1.minute).perform_now
AnyJob.set(wait: 0.1.minute).perform_later더불어, 해당 개념을 통해 perform_now와 perform_later의 명확한 차이를 확인할 수 있는데,
-
AnyJob.set(wait: 0.1.minute).perform_now 작업을 수행 시 wait Time 동안 터미널에서 다른 작업을 할 수 없으나,
-
AnyJob.set(wait: 0.1.minute).perform_later 작업을 수행을 해도 다른 작업을 할 수 있습니다.
2) Queue 이름을 유동적으로(Prefix)
Queue 이름에 있어 유동적으로 사용하도록 지원을 해주는 방식이 존재합니다.
## app/jobs/string_job.rb
class StringJob < ApplicationJob
queue_as :string
def perform(say)
sleep 5
puts "안녕하세요! #{say}번 째 작업에 대한 output입니다."
end
end위 Job 파일 같은 경우는 Queue 이름이 string 으로 되어있습니다.
하지만 만약 Environment에 따라 Queue 이름을 달리하고 싶다면(예 : Production 환경에서는 production_string) 다음과같이 해주면 됩니다.
0. 실습을 위해 새로운 Job을 추가 후, 다음과 같이 코딩을 해주세요.
1) Job 추가
rails g job string
2) app/jobs/string_job.rb 코딩
class StringJob < ApplicationJob
queue_as :string
def perform(say)
sleep 5
puts "안녕하세요! #{say}번 째 작업에 대한 output입니다."
end
end
1. config/application.rb 파일로 이동 후, 다음 코드를 추가합니다.
config.active_job.queue_name_prefix = Rails.env## config/application.rb
module Kcm
class Application < Rails::Application
... (내용 생략) ...
config.active_job.queue_name_prefix = Rails.env
end
end
2. config/sidekiq.yml 파일에서 Queue 목록을 수정합니다.
:pidfile: ./tmp/pids/sidekiq.pid
:daemon: true
development:
:verbose: true
:logfile: ./log/development_sidekiq.log
:concurrency: 2
:timeout: 30
:queues:
- development_string
production:
:verbose: false
:logfile: ./log/production_sidekiq.log
:concurrency: 10
:timeout: 5
:queues:
- production_string
3. 서버, Redis-server, sidekiq 콘솔을 껏다 켜주세요.
4. rails c 를 통해 결과를 확인합니다.

왼쪽 화면에서 @queue_name 부분을 보면 저는 app/jobs/string_job.rb 에서 Queue_as를 development_string 이라고 이름을 지어주지 않았음에도 불구하고 자동으로 Queue_as 명칭 앞에 development가 들어가 있는게 확인이 됩니다.
Tip 하나의 터미널에 여러개의 작업을 띄우기
일반적으로 터미널 하나에는 하나의 작업밖에 띄우지 못합니다.
그렇다고 해서 터미널 여러개를 띄었다 할지라도, 터미널을 끄면 결국 해당 작업에 대해서도 실행이 종료됩니다.
하나의 터미널에 여러개의 작업을 띄우면서도, 터미널을 꺼도 작업이 종료되지 않게 하는 방법은 터미널에 screen 명령어를 입력하시면 됩니다.
부록 Screen에 대한 자세한 개념 [클릭]
-
대기 Queue 작업 전부 지우기

간혹 현재 작업이 미뤄지거나, concurrency 할당작업 초과 등의 사유로 대기 Queue에 작업이 쌓여져 가는 상황이 있습니다. 하지만 이 대기작업이 많이 쌓이게 되면 나중에 큐잉작업 때 순서 혹은 작업이 꼬일 수 있는 이슈가 있습니다.
해당 작업 Queue를 지우는 방법은 간단합니다.
1) 특정 Queue 지우기
# Sidekiq::Queue.new("[Queue 이름]").clear
Sidekiq::Queue.new("mailers").clear
2) 모든 Queue 지우기
Sidekiq::Queue.all.each(&:clear)
-
Redis Key 확인, Redis::Namespace
sidekiq을 실행 시, redis Key에 다음과 같이 key값이 등록된 것을 확인해볼 수가 있습니다.

패턴을 보면 sidekiq_job:... 으로 시작이 되는걸 확인해볼 수 있는데, sidekiq_job 으로 시작하는 이유는 다음 코드속에 있습니다.
과거에 저희는 sidekiq을 설정하면서 config/initializers/sidekiq.rb 파일에 아래와 같이 입력했었습니다.
## config/initializers/sidekiq.rb
# Sidekiq threadpool 생성
REDIS_POOL = ConnectionPool.new(:size => 7 + 5, :timeout => 2) { Redis::Namespace.new("sidekiq_job", redis: Redis.new(:url => "redis://#{ENV['REDIS_HOST']}:6379")) }
# LOG파일 위치 지정
log_file_path = "#{Rails.root}/log/#{Rails.env}_sidekiq.log"
Sidekiq.configure_server do |config|
config.redis = REDIS_POOL
config.logger = Logger.new(log_file_path)
end
Sidekiq.configure_client do |config|
config.redis = REDIS_POOL
end
# [Option] Exception 사유로 Job이 종료가 될 시, 다시 Job 시도 및 횟수를 정하는 코드입니다.
Sidekiq.default_worker_options = {retry: 1}위 코드속에서 잘 보면 다음 아래와 같은 코드를 볼 수 있습니다.
Redis::Namespace.new("sidekiq_job", ...)저희는 위와같이 Redis에서 Namespace를 통해 sidekiq_job 이라는 이름을 지정해준 덕분에 redis의 Key 값에 sidekiq_job:... 이란 키가 등록이 될 수 있습니다.
그리고 위와같은 Namespace 정의를 통해 저희는 다음과 같은 redis URL 규칙을 얻어낼 수 있습니다.
Redis.new
=> redis://127.0.0.1:6379/0
Redis::Namespace.new("sidekiq_job", redis: Redis.new(:url => "redis://127.0.0.1:6379"))
=> redis://127.0.0.1:6379/0/sidekiq_job
Namespace 개념
Namespace을 언급하며 설명을 진행했지만, 정작 Namespace가 뭔지 모를 분들이 있을겁니다.
일단 Namespace란 이름이 동일한 변수, 함수명 등에 있어 독립적인 공간을 제공하도록 돕는 코드영역 이라고 보면 됩니다.
여기서 레일즈 코드 내 config/routes.rb 파일을 예시로 들어보겠습니다.
1. 개발자는 REST API 설계를 해야합니다.
2. 하지만 REST API 내 URI path 중, 버전이 다른 posts에 대한 CRUD path 경로에 대해 정의를 해줘야 하는 상황이 생겼습니다 :
1) posts v1 : api/v1/posts/...
2) posts v2 : api/v2/posts/...
위 사례도 어찌보면 posts와 notices 내에 있는 동일한 CRUD path 경로에 대해 독립적인 공간을 제공하도록 인프라 구현을 해결해야 하는 상황입니다.
레일즈의 라우터 설정 내에서도 이러한 고민을 해결하고자 namespace 가 존재합니다.
namespace를 이용해서 URI path를 설계를 하면 아래와 같은 결과를 얻게 될 수 있습니다.
## routes.rb
namespace :api do
namespace :v1 do
resources :posts
end
namespace :v2 do
resources :posts
end
end
물론, 이렇게도 구현해도 되긴 하겠지만, 흠....... 노가다
## routes.rb
get 'api/v1/posts' => 'api/v1#index'
post 'api/v1/posts' => 'api/v1#create'
get 'api/v1/posts/:id' => 'api/v1#show'
patch 'api/v1/posts/:id' => 'api/v1#update'
put 'api/v1/posts/:id' => 'api/v1#update'
delete 'api/v1/posts/:id' => 'api/v1#destroy'
get 'api/v2/posts' => 'api/v2#index'
post 'api/v2/posts' => 'api/v2#create'
get 'api/v2/posts/:id' => 'api/v2#show'
patch 'api/v2/posts/:id' => 'api/v2#update'
put 'api/v2/posts/:id' => 'api/v2#update'
delete 'api/v2/posts/:id' => 'api/v2#destroy'
다시 redis의 Namespace
다시 Redis의 Namespace로 넘어와서, 그럼 왜 Redis에 Namespace를 썼는지 이해가 갈겁니다.
Redis.new
=> redis://127.0.0.1:6379/0
Redis::Namespace.new("sidekiq_job", redis: Redis.new(:url => "redis://127.0.0.1:6379"))
=> redis://127.0.0.1:6379/0/sidekiq_job단순히 Redis.new로만 했다면 redis://127.0.0.1:6379/0 으로만 끝나다 보니 또 동일한 redis를 생성할 경우, 이름 충돌이 발생할 수 있지만, namespace를 적용한다면 이를 완화할 수 있습니다.
-
Redis Key 패턴 분석

Sidekiq이 작동중인 상태에서 Redis Key를 보면 다음과 같은 패턴을 볼 수 있습니다.
- ${NAMESPACE}:processes
- ${NAMESPACE}:${HOSTNAME}:${PID}:${HASH}
- ${NAMESPACE}:${HOSTNAME}:${PID}:${HASH}:workers
- ${NAMESPACE}:queues
- ${NAMESPACE}:stat:*
## /lib/tasks/job_list.rake
namespace :job_list do
desc "TODO"
task job: :environment do
CrawlAllJob.perform_later()
ModifyAllJob.perform_later()
end
end저는 concurrency가 5인 상황에서 위 task 파일을 돌린 상태에서 redis에 누적되어있는 Key들을 살펴보겠습니다.
1) #{NAMESPACE}:queues
127.0.0.1:6379> type sidekiq_job:queues
set일단 queues 타입을 살펴보고자 위와 같이 입력하면 set이라고 반환을 합니다.
이는 저 queues 안에 value가 있다는 소리입니다.
127.0.0.1:6379> smembers sidekiq_job:queues
1) "crawl_all_job"
2) "modify_all_job"queues value를 살펴보면 제가 task 파일에 등록했던 job들이 확인됩니다.
2) ${NAMESPACE}:processes
127.0.0.1:6379> type sidekiq_job:processes
set이번에는 processes를 분석해보겠습니다.
processes를 보면 이 역시 set 이라고 반환을 합니다.
smembers sidekiq_job:processes
1) "ip-172-31-23-51:5226:4f7f15692bdf"그리고 processes에 등록된 value가 뭔지 보니, 웬 위와같은 value가 나옵니다.

위 value같은 경우는 sidekiq 콘솔 중, identity 객체를 가리킵니다.
3) ${HOSTNAME} : ${PID} : ${HASH}
다음은 NAMESPACE 뒤에 붙는 인자 ${HOSTNAME} : ${PID} : ${HASH} 를 살펴보겠습니다.
127.0.0.1:6379> type sidekiq_job:ip-172-31-23-51:5226:4f7f15692bdf
hash아까와는 다르게 hash라는 값을 리턴합니다.
즉 이 안에는 hash형태로 데이터가 존재한다는 것을 알 수 있습니다.
hash 내부 데이터를 살펴보면 내부 프로세스에 대한 자세한 정보를 알아낼 수 있습니다.
127.0.0.1:6379> hgetall sidekiq_job:ip-172-31-23-51:5226:4f7f15692bdf
1) "beat"
2) "1585245084.5222223"
3) "info"
4) "{\"hostname\":\"ip-172-31-23-51\",\"started_at\":1585244447.7710106,\"pid\":5226,\"tag\":\"catch_job\",\"concurrency\":5,\"queues\":[\"mailers\",\"crawl_all_job\",\"modify_all_job\"],\"labels\":[],\"identity\":\"ip-172-31-23-51:5226:4f7f15692bdf\"}"
5) "quiet"
6) "false"
7) "busy"
8) "0"
4) ${HOSTNAME} : ${PID} : ${HASH} : workers
127.0.0.1:6379> type sidekiq_job:ip-172-31-23-51:5226:4f7f15692bdf:workers
hash이번엔 workers에 대해 살펴보니 이 역시 hash 형태로 데이터가 담겨져 있었습니다.
127.0.0.1:6379> hgetall sidekiq_job:ip-172-31-23-51:5226:4f7f15692bdf:workers
1) "gq7kj4cv2"
2) "{\"queue\":\"modify_all_job\",\"payload\":\"{\\\"retry\\\":true,\\\"queue\\\":\\\"modify_all_job\\\",\\\"class\\\":\\\"ActiveJob::QueueAdapters::SidekiqAdapter::JobWrapper\\\",\\\"wrapped\\\":\\\"ModifyAllJob\\\",\\\"args\\\":[{\\\"job_class\\\":\\\"ModifyAllJob\\\",\\\"job_id\\\":\\\"d4b4b5cc-119f-4c46-b39b-bc4c3d0c58cf\\\",\\\"provider_job_id\\\":null,\\\"queue_name\\\":\\\"modify_all_job\\\",\\\"priority\\\":null,\\\"arguments\\\":[],\\\"executions\\\":0,\\\"locale\\\":\\\"en\\\"}],\\\"jid\\\":\\\"8cf952008b582c8289935db8\\\",\\\"created_at\\\":1585245505.4189746,\\\"enqueued_at\\\":1585245505.423823}\",\"run_at\":1585245505}"해시값을 조회해본 결과, sidekiq 에서 작업중인 Queue의 정보가 조회됩니다.
그런데 여기서 눈에띄는건 1번 째 해시에 담겨져 있는 "gq7kj4cv2" 입니다.
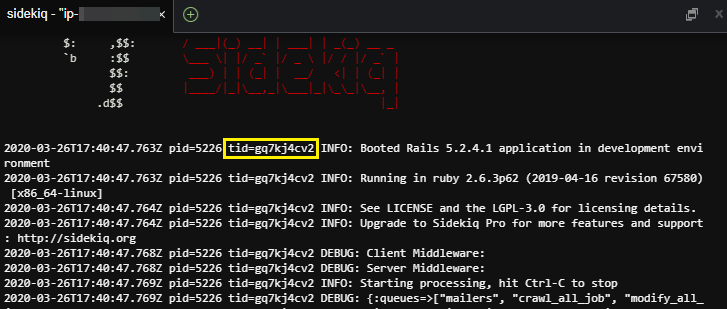
gq7kj4cv2는 tid의 값으로서, thread의 ID값을 가리킵니다.
또한, 5226 값을 가진 pid는 프로세스 ID값을 가리킵니다.
ps -ef | grep sidekiq실제로 위 명령어를 입력해서 sidekiq의 PID 값을 조회해보면 아래와 같은 결과를 얻어볼 수 있습니다.

5) queue : ${QUEUE}${NAMESPACE}:stat:*
stat 같은 경우는 모든 key에 있어 전부 string 형태를 띄고 있습니다.
127.0.0.1:6379> type sidekiq_job:stat:processed
string
127.0.0.1:6379> type sidekiq_job:stat:failed
string
127.0.0.1:6379> type sidekiq_job:stat:processed:2020-03-26
string
127.0.0.1:6379> type sidekiq_job:stat:failed:2020-03-26
string
내부를 보면 sidekiq 수행 및 실패에 대한 횟수를 볼 수 있습니다.
* 아래 key에 대한 분석은 다른 서버에서 분석해봤습니다.
127.0.0.1:6379> get sidekiq_job:stat:processed
"183"
127.0.0.1:6379> get sidekiq_job:stat:processed:2020-03-25
"52"
127.0.0.1:6379> get sidekiq_job:stat:processed:2020-03-26
"131"
127.0.0.1:6379> get sidekiq_job:stat:failed
"0"
127.0.0.1:6379> get sidekiq_job:stat:failed:2020-03-25
"0"
127.0.0.1:6379> get sidekiq_job:stat:failed:2020-03-26
"0"더불어 뒤에 날짜가 붙는다면 해당 날에 한정지어 기록을 가진걸로 보입니다.
-
부록 각각의 queue 마다 MAX concurrency 지정
각각의 Queue 별로 최대로 허용하고 싶은 concurrency를 설정하고 싶은 경우가 있을겁니다.
## config/sidekiq.yml
production:
:verbose: false
:logfile: ./log/production_sidekiq.log
:concurrency: 3
:timeout: 30
:queues:
- send_mail_report
- check_process
- date_check
:limits:
date_check: 1
check_process: 2위 코드를 예시로 들자면, 전체 concurrency 중, Queue : date_check 같은 경우는 최대 1개만, check_process는 최대 2개까지만 queue concurrency를 허용하는겁니다.
1. Limit Queue 갯수 설정을 도와주는 Gem을 추가적으로 설치합니다.
Gemfile 파일을 열람 후, 아래 코드를 추가해주세요.
gem 'sidekiq-limit_fetch'그리고 Gem을 설치해주세요.
bundle install
2. config/sidekiq.yml 파일을 열람 후, 아래와 같이 concurrency를 제한하고 싶은 queue를 따로 설정해주세요.
## config/sidekiq.yml
production:
:verbose: false
:logfile: ./log/production_sidekiq.log
:concurrency: 3
:timeout: 30
:queues:
- send_mail_report
- check_process
- date_check
:limits:
date_check: 1
check_process: 2
3. sidekiq을 Ctrl+C 로 끈 후, 다시 터미널에 명령어를 입력해서 실행 합니다.
## Development Environment
sidekiq
## Production Environment
RAILS_ENV=production sidekiq
- Tip Heroku에 Redis-server + 사이드킥 배포
주의
Heroku에서는 Sidekiq을 사용 시, Heroku 사용 시간으로 간주됩니다.
(30일 기준, 기본적인 서버실행 720시간 + Sidekiq 실행 720시간 = 1440시간)
헤로쿠에서 Sidekiq을 실행할려 하면 Redis-server의 부재로 인한 오류가 발생하게 됩니다.

해당 문제에 대한 해결 방법은 다음 과정을 따라주면 됩니다.
1. 아래 URL로 이동해서 Redis-server Add-On을 설치합니다.
https://elements.heroku.com/addons/heroku-redis
Add-On을 설치하면 헤로쿠 작업 기록에는 다음과같이 redis 설치 관련 기록이 남게됩니다.

2. sidekiq 명령어를 Background 방식으로 실행을 해줘야 하는 과제가 남아있습니다.
레일즈 프로젝트에 있어 루트폴더 위치(Gemfile, Gemfile.lock 파일 등이 있는 곳)에 Procfile 파일 을 생성합니다.
3. Procfile 에 다음 내용을 작성합니다.
web: bundle exec puma -C config/puma.rb
worker: bundle exec sidekiq -c 2참고 Enque Background Job를 위해 Heroku 서버 Process 추가를 위한 작업
4. Heroku에 배포합니다.
git add .
git commit -m "Procfile add for sidekiq"
git push heroku master
5. 헤로쿠와 연동된 터미널에 다음 명령어를 입력해서 헤로쿠의 서버작업 Process를 추가 합니다.
heroku ps:scale worker=1
=> Scaling dynos... done, now running worker at 1:Free6. 헤로쿠와 연동된 터미널에
heroku info위의 명령어를 입력해서 worker이 잘 추가되었는지 확인합니다.

7. 최종적으로 Heroku에 Deploy된 내 홈페이지의 사이드킥 관리창으로 이동 후, 프로세스가 잘 만들어졌는지 확인합니다.
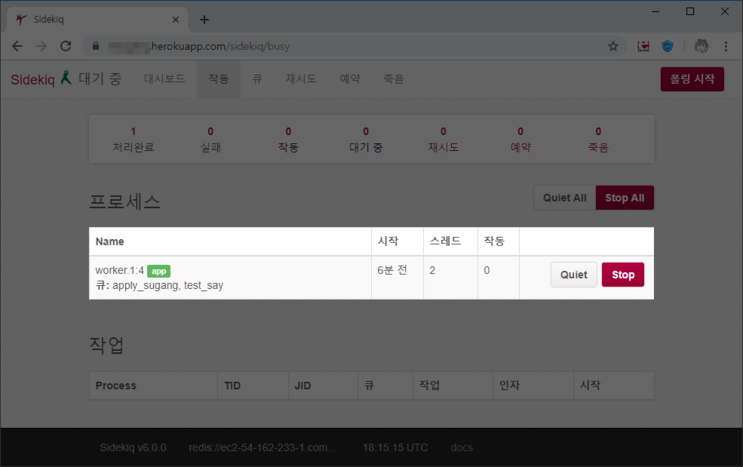
8. 헤로쿠 터미널에서도 Job을 테스트 해볼 수 있습니다.
1) 헤로쿠와 연동된 터미널에서 다음 명령어를 통해 Heroku 서버 내 Rails Console로 이동합니다.
heroku run rails c
2) 기존과 같이 Background Job을 테스트해보세요.
AnyJob.perform_later("하이")
- 주의사항 사이드킥 테스트 시 주의사항
1. 파일 내용이 바뀌면 sidekiq 콘솔을 껏다 켜서 테스트를 해주세요.
파일 내용이 바뀌고, 파일을 저장을 했다 해서 Console까지 적용되는게 아니라서 처음에 테스트할 때 많이 실수했습니다.
2. Sidekiq에서 허용되는 Queue 목록을 잘 확인하세요.

수정된 config/sidekiq.yml 에 대해 큐를 최신화 하는 방법은 sidekiq을 재가동 하면 됩니다.
- 자료 참고
2. config/initializers/sidekiq.rb 서버/클라이언트 개별 설정 이유
4. Difference between PID and TID
5. 네임스페이스 개념
6. sidekiq 설치
10. To limit concurrency on individual queue
'프로그래밍 공부 > Ruby on Rails : Gem' 카테고리의 다른 글
| Ruby on Rails : Nokogiri 크롤링 [Gem : nokogiri] (0) | 2019.12.05 |
|---|---|
| Ruby on Rails : DB 백업하기 (PostgresDB 기준 설명) [Gem : backup, whenever] (0) | 2019.12.05 |
| Ruby on Rails : 스케쥴링(예약된 시간) Background Job [Gem : Whenever] (0) | 2019.12.03 |
| Ruby on Rails : 중첩댓글 [Gem : act-as-commentable-with-threading] with Ajax 비동기 처리 (6) | 2019.11.05 |
| Ruby on Rails : 띵동! 알람잼 [Gem : unread] (0) | 2019.11.05 |
