
티스토리 뷰
- Intro
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산, RESTful API 기반의 검색엔진 입니다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
- 목차
0. 용어 정리
1. Get Elasticsearch up and running
4. Analyze results with aggregations
5. 자료 참고
- 용어정리
해당 문서를 읽기전에 앞서, 우리에게 낯이 익는 단어들(document, index, shard 등)이 많이 보여집니다.
그렇다보니 사전에 용어를 알고 문서를 읽으면 이해에 있어 많은 도움이 될 것으로 예상됩니다.
저는 ElasticSearch을 공부하면서 용어에 대한 정리는 이 문서에서 많은 도움을 받았습니다.
- Get Elasticsearch up and running
test drive를 위해 Elasticsearch를 사용하려면, Elasticsearch Service에서 호스팅 배포를 생성하거나 자체 Linux, macOS 또는 Windows 시스템에서 multi-node Elasticsearch 클러스터를 설정할 수 있습니다.
Elasticsearch Service에서 배포를 생성하면 서비스는 Kibana 및 APM과 함께 three-node Elasticsearch 클러스터를 프로비저닝합니다.
Run Elasticsearch on Elastic Cloud
deployment 생성을 위해 다음 과정을 거쳐야 합니다 :
1. Elastic Search에 free trial 기반으로 회원가입 진행
2. 계정에 비밀번호 설정
3. Elastic Search 대시보드에서 Create Deployment 버튼을 클릭해서 자신의 환경에 맞게 설정 후 새 프로젝트 생성

development를 생성을 완료했다면, 다음 과정인 Index some documents를 해낼 준비가 됐습니다.
Run Elasticsearch locally on macOS
Elasticsearch Service에서 배포를 생성하면 Master Node와 두 개의 Data Node가 자동으로 프로비저닝됩니다. tar 또는 zip 확장자의 파일을 통해 설치하면 여러개의 Elasticsearch instance를 local에서 시작하여 multi-node 클러스터의 작동 방식을 확인할 수 있습니다.
three-node Elasticsearch cluster을 설치하기 위해선 다음 과정을 진행해주세요 :
참고 1 Mac OS 환경, zsh 에서 설치하는 과정을 기준으로 합니다.
참고 2 시행착오를 줄이고 싶다면 되도록 Oracle Java 8(1.8)을 사용하는 것을 권장합니다.
1. ElasticSearch는 Java 기반의 오픈소스라고 앞전에 설명되어 있는 만큼, 결국 Java를 설치해야 할 필요가 있습니다.
java 설치 전에 있어, 자바의 버전을 관리해주는 jenv 패키지(루비로 치면 rbenv 개념)를 설치합니다.
brew install jenv
2. 터미널이 켜지자마자 실행될 script(jenv 관련)를 zshrc에 등록합니다.
echo 'export PATH="$HOME/.jenv/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(jenv init -)"' >> ~/.zshrc
source ~/.zshrc
3. AdoptOpenJDK 8을 설치합니다.
brew tap AdoptOpenJDK/openjdk
brew install --cask adoptopenjdk8
참고 기존의 brew cast install은 2020-12-31 에 deprecated 되었습니다.
4. 아래 Oracle 사이트에 가서 Mac OS를 지원하는 OracleJDK8을 다운로드 및 설치합니다.
참고 Oracle 사이트에 회원가입 및 로그인을 해야 파일이 다운로드 됩니다.

5. 터미널을 통해 jenv에 add 합니다.
참고 아래 script에서 [version] 부분은 자신이 설치한 버전에 맞게 숫자 입력..
# jenv add /Library/Java/JavaVirtualMachines/jdk1.8.0_[version].jdk/Contents/Home
jenv add /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home
6. jenv에 설정이 잘 되어 있는지 versions 명령을 확인해보세요. 설치된 JDK 버전에 따라 표시되는 내용은 다르겠지만 아래와 비슷한 형태를 가질 겁니다. 리스트를 보면 1.8.0.261, 1.8과 같은 숫자도 같이 표시되는 것을 의아하게 생각할 수도 있겠지만 이것은 일종의 alias처럼 동작이 되는 값이니 신경 쓰지 않아도 됩니다.
jenv versions system
1.8
* 1.8.0.261 (set by /Users/kcm/.java-version)
oracle64-1.8.0.261
7. 터미널 창에 jenv에 plugin 을 활성화
jenv enable-plugins maven
jenv enable-plugins export
8. 모든 터미널에 대해 java의 특정 버전을 사용하도록 유도합시다.
참고 아래 script에서 [version] 부분은 자신이 설치한 버전에 맞게 숫자 입력.. 이 예시에서는 1.8.0.261 이겠죠?
jenv global 1.8.0.[Version]
9. 마지막으로 java가 잘 설치되었는지 확인해봅시다.
java -version
10. Elasticsearch 최신버전을 확인합니다.
20. 7. 22 기준, 최신버전은 6 인게 확인됩니다.
brew search elasticsearch
11. Elasticsearch를 설치합니다.
저는 최신버전으로 설치하겠습니다.
brew install elasticsearch@6.8
12. 터미널이 켜지자마자 실행될 script(elasticsearch 관련)를 zshrc에 등록합니다.
echo 'export PATH="/usr/local/opt/elasticsearch@6/bin:$PATH"' >> ~/.zshrc
13. .zshrc 최신 반영 후, elasticsearch를 실행해 봅시다.
source .zshrc
elasticsearch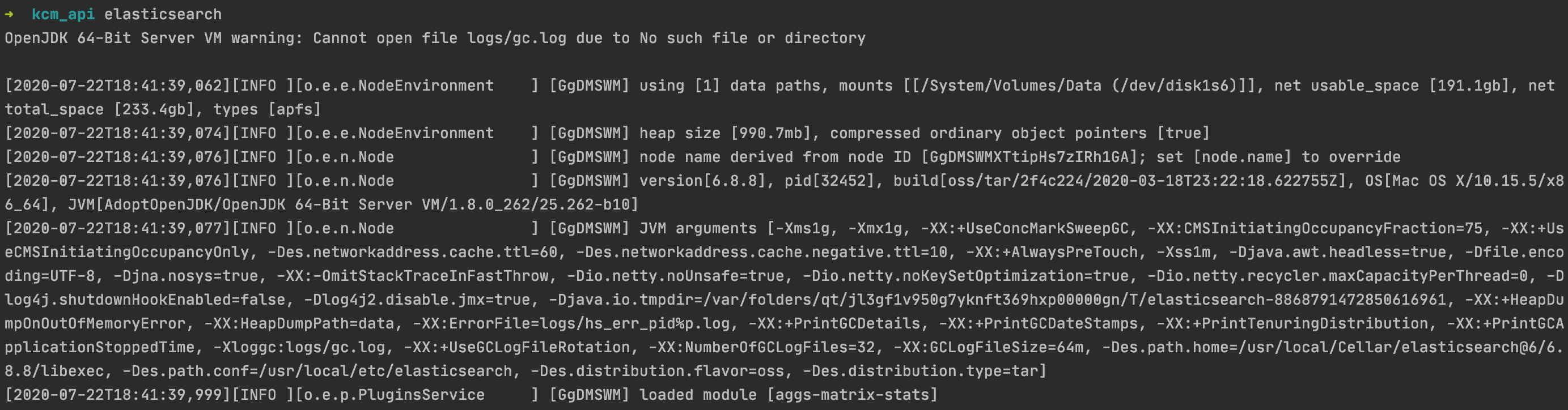
위와같이 elasticsearch 서버가 터미널에서 9200 Port로 돌아가면 성공입니다.
14. 일반적인 multi-node cluster의 동작을 확인할 수 있도록 Elasticsearch instance를 두개 더 시작하세요. 각 node에 고유 데이터 및 로그 경로를 지정해야합니다.
elasticsearch -Epath.data=data2 -Epath.logs=log2
elasticsearch -Epath.data=data3 -Epath.logs=log3
추가 node에는 고유 ID(unique ID)가 할당됩니다. 세 개의 노드를 모두 local에서 실행하기 때문에 첫 번째 node와 cluster에 자동으로 연결됩니다.
5. cat health API를 사용하여 three-node cluster가 실행 중인지 확인하세요.
cat API는 indices(index의 복수) JSON보다 읽기 쉬운 형식으로 cluster 및 색인(index)에 대한 정보를 반환합니다.
Elasticsearch REST API에 HTTP 요청을 제출하여 cluster와 직접 통신(상호작용)을 할 수 있습니다. 이 안내서의 대부분의 예제에 맞는 cURL 명령을 복사하고 터미널에서 local Elasticsearch instance로 request를 제출할 수 있습니다. Kibana가 설치되어 실행중인 경우 Kibana를 열고 Dev Console을 통해 request을 할 수도 있습니다.
참고 Application에서 Elasticsearch를 사용할 준비가 됐다면 Elasticsearch language clients 문서를 참고해주세요.
curl -X GET http://localhost:9200/_cat/health?v만약 서버 앞으로 위의 request을 보내면 return되는 response는 elasticsearch cluster의 상태가 green이고, 세 개의 node가 있음을 표시되어야 합니다.

참고 status에 대한 상태는 다음과 같습니다 :
- yellow : 단일 instance만 실행, 단일 노드 cluster는 완벽하게 작동하지만 복원력을 제공하기 위해 데이터를 다른 node로 복제 할 수 없습니다.
- green : Replica shards(원본 데이터에 문제가 생겼을 때, 그 역할로 쓰이는 장애극복 역할로서 쓰임)를 사용할 수 있음
- red : 일부 데이터 사용 불가
- Index some documents
Document는 엘라스틱서치 데이터의 최소 단위이며, JSON Object 하나 입니다. 관계형 데이터베이스에서 테이블의 행에 해당하는 것입니다.
cluster가 시작되면 일부 데이터를 색인(index)할 수 있습니다. Elasticsearch에는 다양한 수집 옵션이 있지만 결국 모두 동일한 작업을 수행합니다. PUT JSON documents(elasticsearch 데이터의 최소 단위이며, JSON Object 하나)를 Elasticsearch 색인에 넣습니다.
request body에 document를 추가 할 index, document ID 및 하나 이상의 "field": "value" 쌍을 지정하는 간단한 PUT 요청을 수행할 수 있습니다.
## Request Method 및 URI
PUT /customer/_doc/1
## Request body
{
"name": "John Doe"
}
이 request는 customer index이 없는 경우, 자동으로 customer index을 작성하고 ID가 1인 새 document를 추가한 후 name 필드를 저장하고, 색인화(index) 합니다.
최초 document 생성 시, document의 version은 1로 표기됩니다.
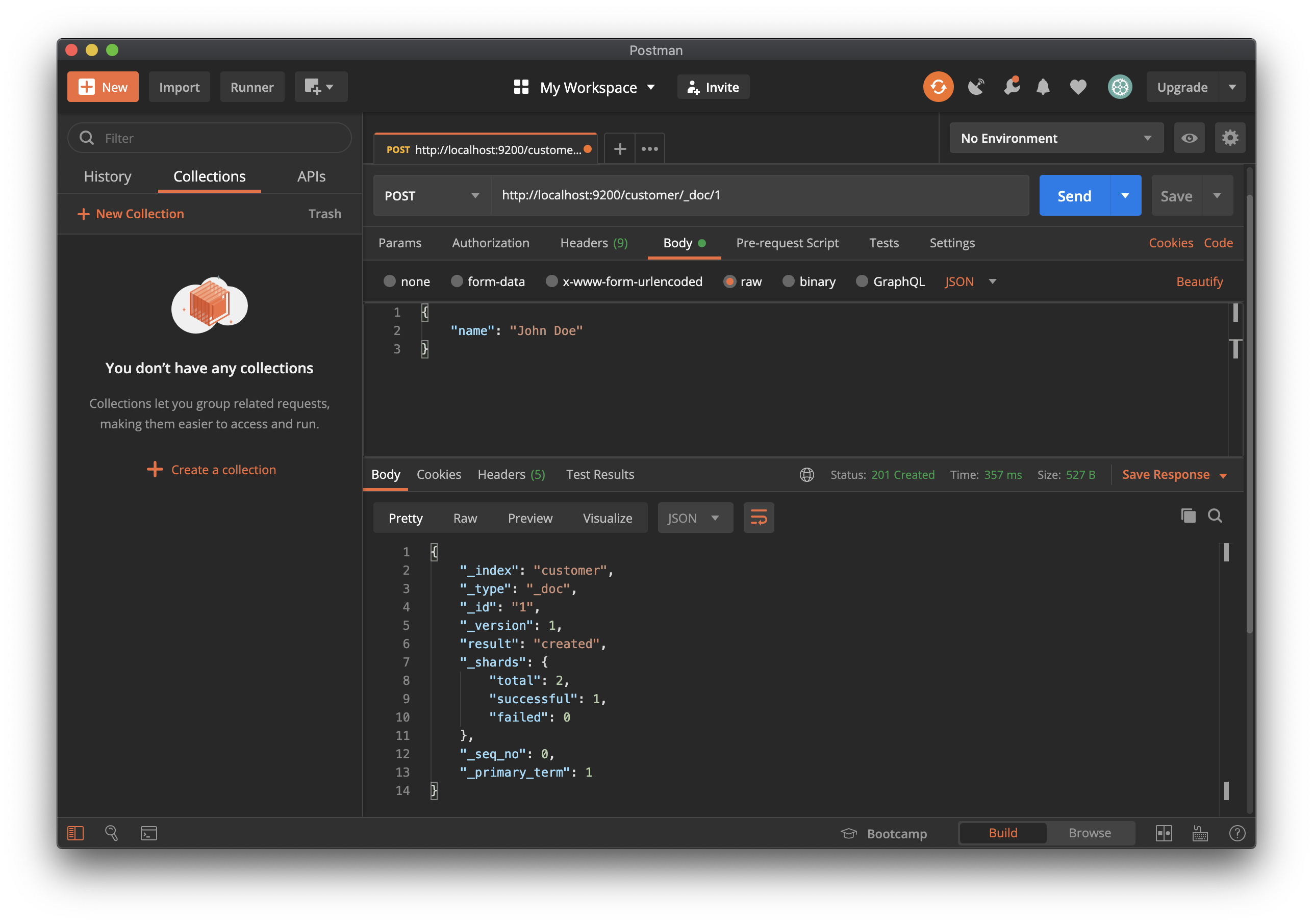
새 document는 cluster의 모든 node에서 바로 사용할 수 있습니다.
document ID를 지정하는 GET 요청으로 이를 검색할 수 있습니다.
GET /customer/_doc/1response는 지정된 document의 ID를 탐색 후, 색인화 된 원래 source field를 표시합니다.
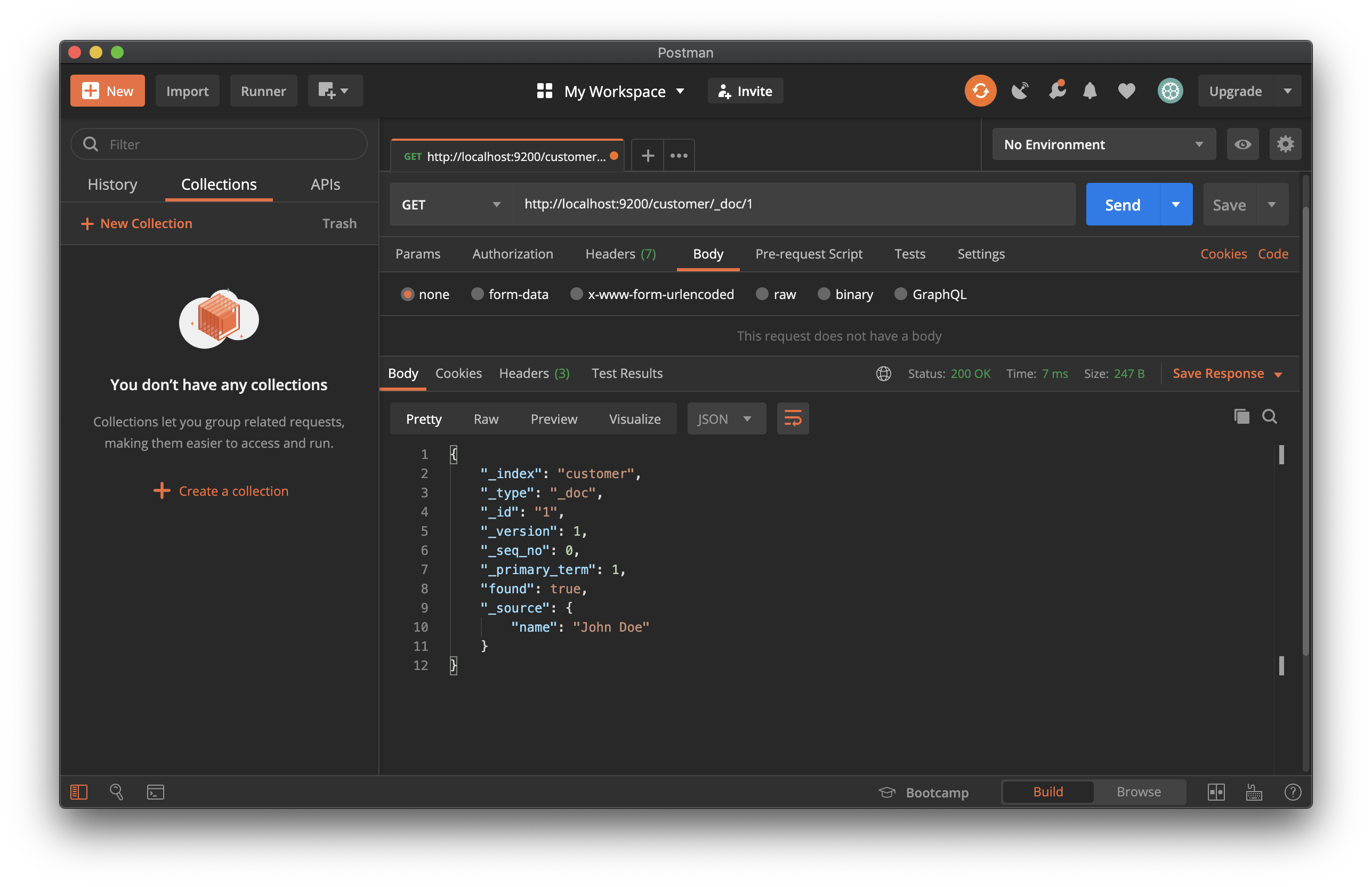
Indexing documents in bulk
색인화 할 document가 많은 경우, bulk API를 사용하여 한번에(batch) 제출할 수 있습니다. 일괄 작업(batch)을 활용 시, 네트워크 roundtrips(왕복)을 최소화 하므로 request를 개별적으로 제출하는 것보다 훨씬 빠릅니다.
최적의 batch 크기는 document 크기(size) 및 복잡성(complexity), 인덱싱(indexing) 및 검색로드, cluster에서 사용 가능한 resources 등 여러가지 요소에 따라 다릅니다. batch 작업에 좋은 size는 1,000 ~ 5,000 개의 documents, 5MB~15MB 사이의 total payload 입니다. 또한 여기서 sweet spot을 찾기 위한 실험도 할 수 있습니다.
검색 및 분석을 시작할 수 있는 일부 데이터를 Elasticsearch로 가져 오려면 다음을 수행하십시오. :
1. accounts.json sample data 파일을 다운로드 하세요. 해당 파일의 json 내용은 아래 정보를 가진 사용자 계좌 정보를 보여줍니다.
## accounts.json 데이터 중 일부
{
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}
2. 아래와 같이 _bulk request를 통해 account 데이터를 bank index에 색인화 하세요.
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json"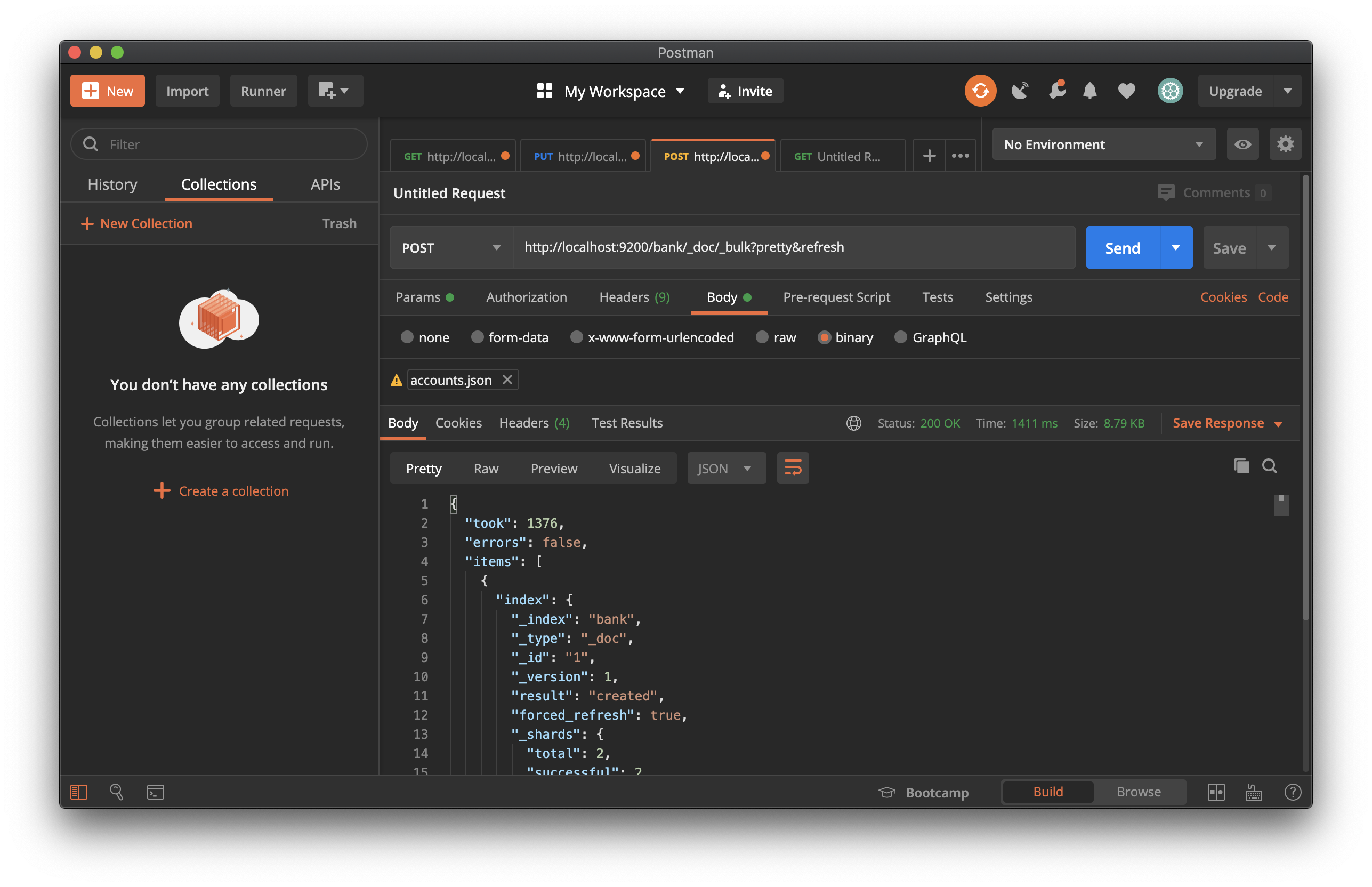
3. bank에 대한 json 데이터를 색인화(index) 후, 색인 결과를 한번 볼까요?
curl -X GET http://localhost:9200/_cat/indices?v
터미널에 위 명령어를 통해 각 색인 데이터의 작업 결과를 확인할 수 있습니다.
위 명령어를 통해 이전에 indexing을 작업했던 결과에 대해 document 생성이 성공적(health: green)으로 됐다는 response가 확인됩니다.

- Start searching
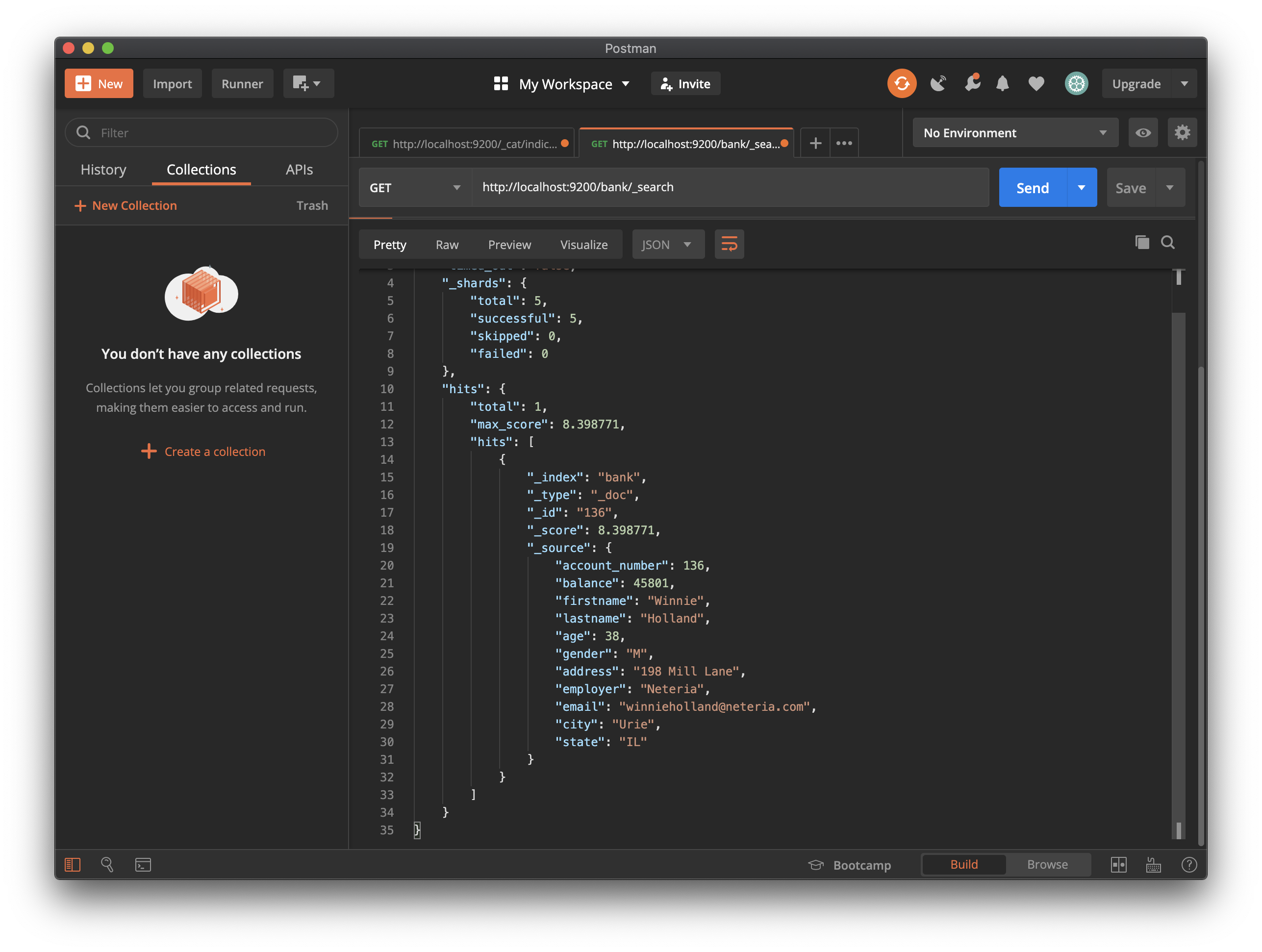
Elasticsearch 색인으로 일부 데이터를 수집 한 후에는 _search 엔드 포인트로 request를 보내서 데이터를 검색할 수 있습니다. 전체 검색 기능에 접근하려면 Elasticsearch Query DSL('SQL 문법' 이라고 이해하면 됩니다.)을 사용하여 요청 본문에 검색 기준을 지정하면 됩니다. 요청 URI에서 검색하려는 색인의 이름을 지정하세요.
예를 들어, 아래 요청은 계좌번호(account_number) 별로 정렬된 은행 index의 모든 document를 검색합니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}기본적으로 응답 결과 섹션에는 검색 기준과 일치하는 10개의 문서(오름차순 정렬)가 포함됩니다.
{
"took" : 63,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1000,
"max_score": null,
"hits" : [ {
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"sort": [0],
"_score" : null,
"_source" : {"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F","address":"244 Columbus Place","employer":"Euron","email":"bradshawmckenzie@euron.com","city":"Hobucken","state":"CO"}
}, {
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"sort": [1],
"_score" : null,
"_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, ...
]
}
}
respons는 검색 request에 대한 다음 정보를 제공합니다. :
took – Elasticsearch에서 쿼리를 실행하는 데 걸린 시간 (milliseconds)
timed_out – 검색 request Time이 초과되는지 여부
_shards – 검색된 샤드(index의 document를 분산 저장하는 저장소) 수와 성공, 실패 또는 건너 뛴 샤드 수에 대한 분석
max_score – 가장 관련성이 높은 문서의 점수
hits.total.value - 일치하는 document 수
hits.sort - document의 정렬 위치 (관련성 점수별로 정렬하지 않은 경우)
hits._score - 문서의 관련성 점수 (match_all을 사용할 때는 해당되지 않음)
각 검색 request는 자체 포함됩니다. : Elasticsearch는 request에 대한 state information를 유지하지 않습니다. 검색 조회를 페이징하려면 요청에서 시작 및 크기 매개 변수를 지정하세요.
예를 들어 아래 요청은 10(from이 10)에서 19(size이 10) 사이의 조회를받습니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
],
"from": 10,
"size": 10
}기본 검색 요청을 제출하는 방법을 살펴 봤으므로 이제 match_all보다 약간 흥미로운 검색어를 작성해보겠습니다.
필드 내에서 특정 용어를 검색하기 위해 일치 쿼리를 사용할 수 있습니다. 예를 들어 다음 요청은 주소 필드를 검색하여 address에 mill 또는(or) lane이 포함 된 고객을 찾습니다. :
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": { "match": { "address": "mill lane" } }
}
개별 용어와 일치하지 않고 구문 검색을 수행하려면 match 대신 match_phrase를 사용하세요.
아래 예시는 mill lane 글자가 일치하는 address 데이터만 찾아냅니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": { "match_phrase": { "address": "mill lane" } }
}
보다 복잡한 Query를 구성하기 위해 bool Query를 사용하여 여러 Query 기준을 결합할 수 있습니다. 필요에 따라 required(must match), desirable(should match), undesirable(must not match) 기준을 지정할 수 있습니다.
예를 들어, 아래 요청은 bank index에서 40세 고객의 계정을 검색하지만, Idaho(state code: ID)에 사는 사람은 제외합니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}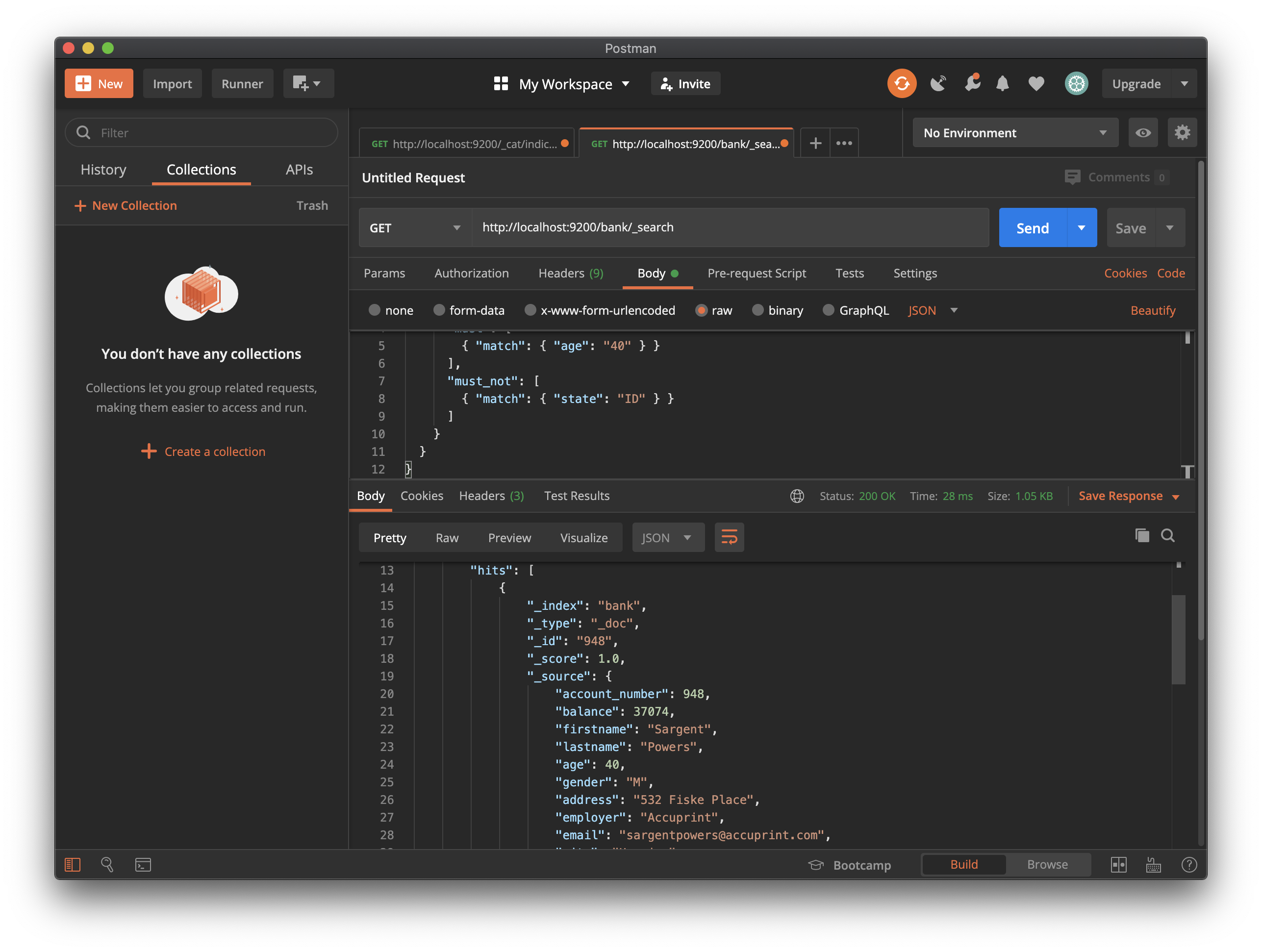
Boolean Query의 각 must, should, must_not 요소를 Query clause 라고 합니다. document가 각 must clause 또는 should clause의 기준을 얼마나 잘 충족 시키는가 document의 관련성 점수에 기여합니다. 점수가 높을수록 document가 검색 기준과 더 잘 일치합니다. 기본적으로 Elasticsearch는 이러한 관련성 점수로 순위가 지정된 document를 반환합니다.
must_not clause의 기준은 필터로 처리됩니다. document가 결과에 포함되는지 여부에 영향을 주나, 채점 방법에는 영향을 미치지 않습니다. 구조화 된 데이터를 기반으로 document를 포함하거나 제외하도록 임의 필터를 명시적으로 지정할 수 있습니다.
예를 들어 다음 요청은 범위 필터를 통해 잔액(balance)이 $ 20,000-$ 30,000 (inclusive; 포함) 인 계정으로 결과를 제한합니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
- Analyze results with aggregations
Elasticsearch 집계를 사용하면 검색 결과에 대한 meta-information을 얻고, "How many account holders are in Texas?", "What’s the average balance of accounts in Tennessee?" 와 같은 질문에 답할 수 있습니다. 한 번의 요청으로 document 검색, filter hits, 집계를 사용하여 결과 분석을 해낼 수 있습니다.
아래 request 예시는 terms 집계를 활용해서 bank index의 모든 계정을 state(미국 주)로 그룹화하고, 가장 많은 state 그룹을 내림차순으로 반환합니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
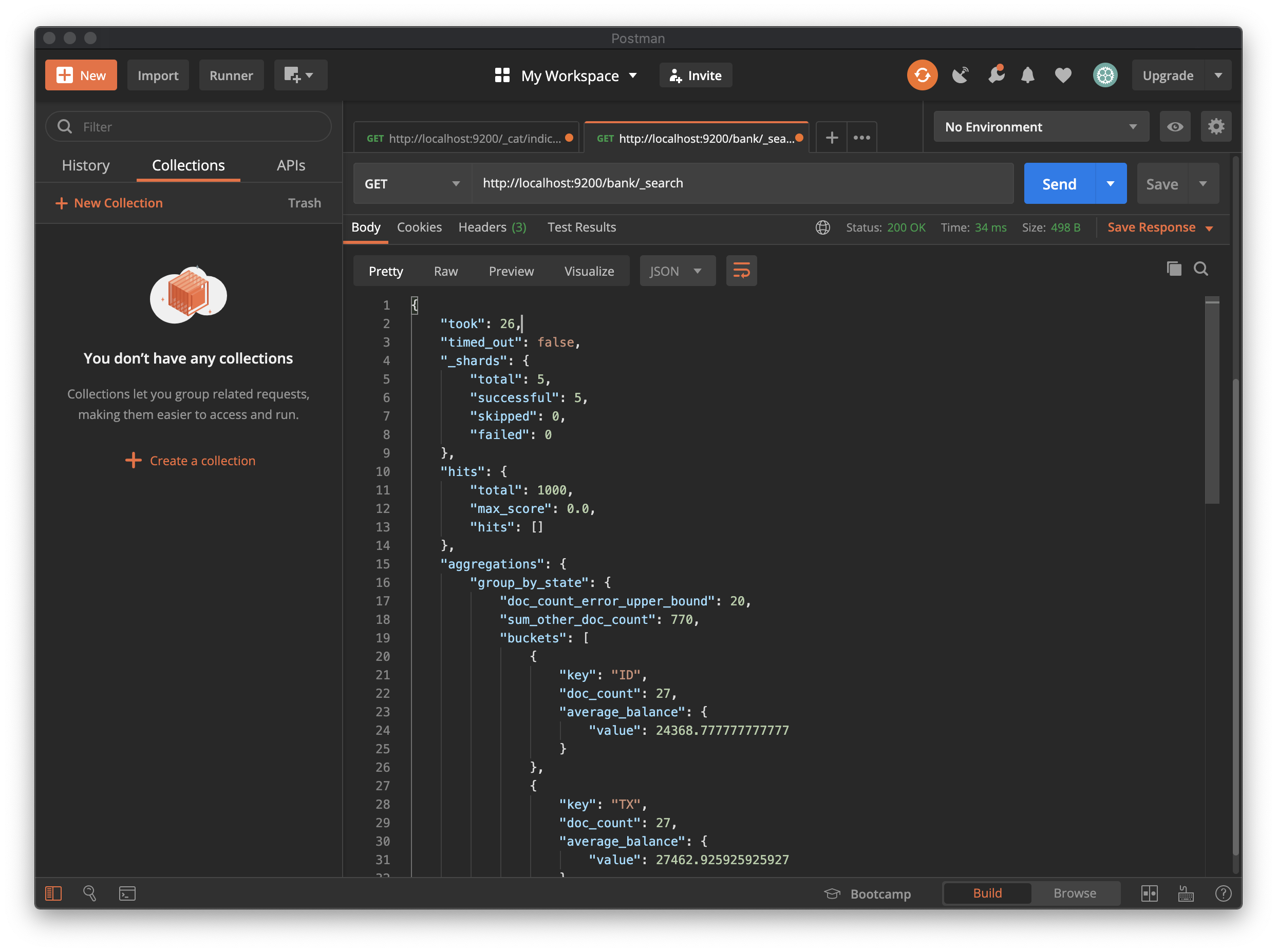
응답의 buckets은 state field의 값입니다. doc_count는 각 상태의 계정 수를 보여줍니다. 예를 들어 ID(Idaho)에 해당하는 계정은 27개가 있음을 알 수 있습니다. 요청 세트 크기가 0이므로 응답에 집계 결과 만 포함됩니다.
집계를 결합하여보다 복잡한 데이터 요약을 작성할 수 있습니다. 예를 들어 아래 request는 이전 group_by_state 집계 내에 평균 집계(avg)를 중첩하여 각 상태의 평균 계정 잔액(balance)을 계산합니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
결과를 개수별로 정렬하는 대신, terms aggregation 내에서 순서를 지정하여 중첩 집계의 결과를 사용하여 정렬 할 수 있습니다.
## Request Method 및 URI
GET /bank/_search
## Request body
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
이와 같은 기본 bucket 및 metrics 집계 외에도 Elasticsearch는 여러 field에서 작동하고 날짜, IP 주소 및 위치(geo) 데이터와 같은 특정 유형의 데이터를 분석하기위한 특수 집계를 제공합니다. 추가 분석을 위해 개별 집계 결과를 파이프 라인 집계에 제공 할 수도 있습니다.
집계에서 제공하는 핵심 분석 기능을 통해 머신 러닝을 사용하여 이상을 탐지하는 등의 고급 기능을 사용할 수 있습니다.
- 자료 참고
'프로그래밍 공부 > TIL : Rails Tutorial' 카테고리의 다른 글
| Chapter 14 : Serializers (0) | 2020.07.20 |
|---|---|
| Chapter 13 : JSend (0) | 2020.07.18 |
| Chapter 12 : Debugging Rails Applications (0) | 2020.07.18 |
| Chapter 11 : Testing Rails Applications (0) | 2020.07.16 |
| Chapter 10 : Using Rails for API-only Applications (0) | 2020.07.14 |
